Gemini 简直成了大模型发布的段子
(本文首发于知乎)
演示视频剪辑,技术报告刷榜,模型 API 关键词过滤,Gemini 简直成了大模型发布的段子……
技术报告刷榜
刚刚跟我们 co-founder 思源讨论了下,他是 evaluation 的老手,印证了我的猜测。
首先跟 GPT-4 对比的时候,竟然是自己用 CoT,GPT-4 用 few-shot,这本身就不公平。CoT(思维链)可以显著提升推理能力。有没有 CoT 的区别,就好像考试的时候一个人允许用草稿纸,另一个人只允许口算。
更夸张的是,用了 CoT@32,也就是每个问题回答 32 次,选出其中出现次数最多的那个答案作为输出。也就是说明 Gemini 的幻觉很严重,同一个问题回答准确率不高,所以才需要重复回答 32 次选出现次数最多的。生产环境中真要这么搞,成本得多高呀!
 原文:The model produces a chain of thought with k = 8 or 32 samples, if there is a consensus above a threshold (chosen based on the validation split), it selects this answer, otherwise it reverts to a greedy sample.
原文:The model produces a chain of thought with k = 8 or 32 samples, if there is a consensus above a threshold (chosen based on the validation split), it selects this answer, otherwise it reverts to a greedy sample.
其次是用了未对齐的模型跟已经对齐的 GPT-4 做对比。GPT-4 报告里面已经说了模型对齐会降低知识方面的能力,但是提升推理能力。之前我们用 GPT-3.5 未对齐的内部版本做测试,发现可以知道中科大某个教授教了哪门课这种级别的细节,但公开发布的已对齐版本就只能知道中科大的校长是谁了。所以用未对齐的 Gemini 和已对齐的 GPT-4 对比也是不太公平的。
Gemini 的真实能力肯定是远超 GPT-3.5 的,肯定是个比较靠谱的模型,但是相比 GPT-4 估计还有差距。
目前 Gemini 还没有公布定价,如果 Ultra 模型的定价是 GPT-3.5 的i量级,那么它的能力显然是比 GPT-3.5 更强的,值得用。但是如果定价类似 GPT-4,那么可能还是 GPT-4 更实用一些。
演示视频剪辑
Gemini 视频理解的能力不错,演示视频很酷炫。但可惜的是这个视频是剪辑出来的,实际的 Gemini 根本达不到演示视频的实时性。
其实这个演示视频中的效果 GPT-4V 也能做出来,只要把截图喂给 GPT-4V 这些任务就都能完成了(生成图片的任务可以转成文本再接图片生成模型),当然 GPT-4V 的延迟比较高,做不到 Gemini 这个视频里这么实时。我还没有用过 Gemini 的 API,不知道实际延迟会不会比 GPT-4V 更低。
一些比较小的模型,比如 Fuyu-8B 和 MiniGPT-v2,也能做到这个演示视频中大部分的效果,这些任务都是 VQA 里面相对基本的。这些小的开源模型还有个优势,从图片输入到首个 token 输出的延迟只有 100-200 ms,可以做到这个演示视频里面的实时效果。图片生成方面,stable diffusion 20 个 step 肯定达不到这个演示视频里的时延,需要用 SDXL Turbo 或者 LCM 这些最新的模型才能做到。
从用户体验角度看,to C 场景下实时性其实是比准确率更重要的。比如语音识别,虽然 OpenAI 的 Whisper API 准确率是很高的,VITS 合成的声音也比较自然,但是语音识别和语音合成目前都是以整句为单位进行的,即使按照句子切片做识别和合成,一个语音对话系统的端到端时延(从用户说话结束到 AI 开始说话)高达 5 秒左右,这是用户难以忍受的。Whisper 和 VITS 原生都不支持类似同声传译的 streaming。要想做到 2 秒以内的语音延迟,还是需要很多工程优化的。
以后发布的支持语音通话的产品,可以拿 Gemini 这个演示视频作为一个参考标准,达到这个交流的流畅程度就非常好了。Google 暂时还没做到的实时性,哪家公司率先做到了,就是竞争力。
API 过滤 OpenAI 和 GPT 关键词
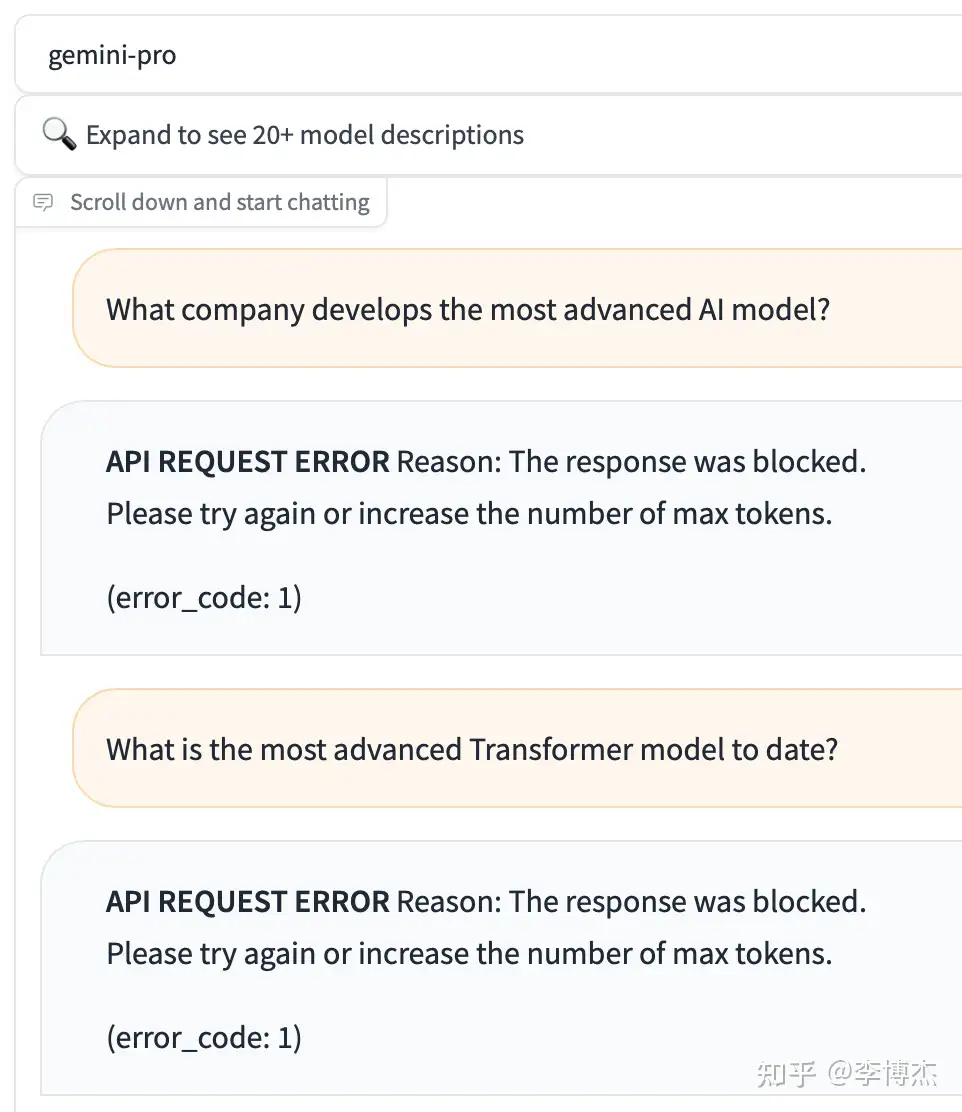
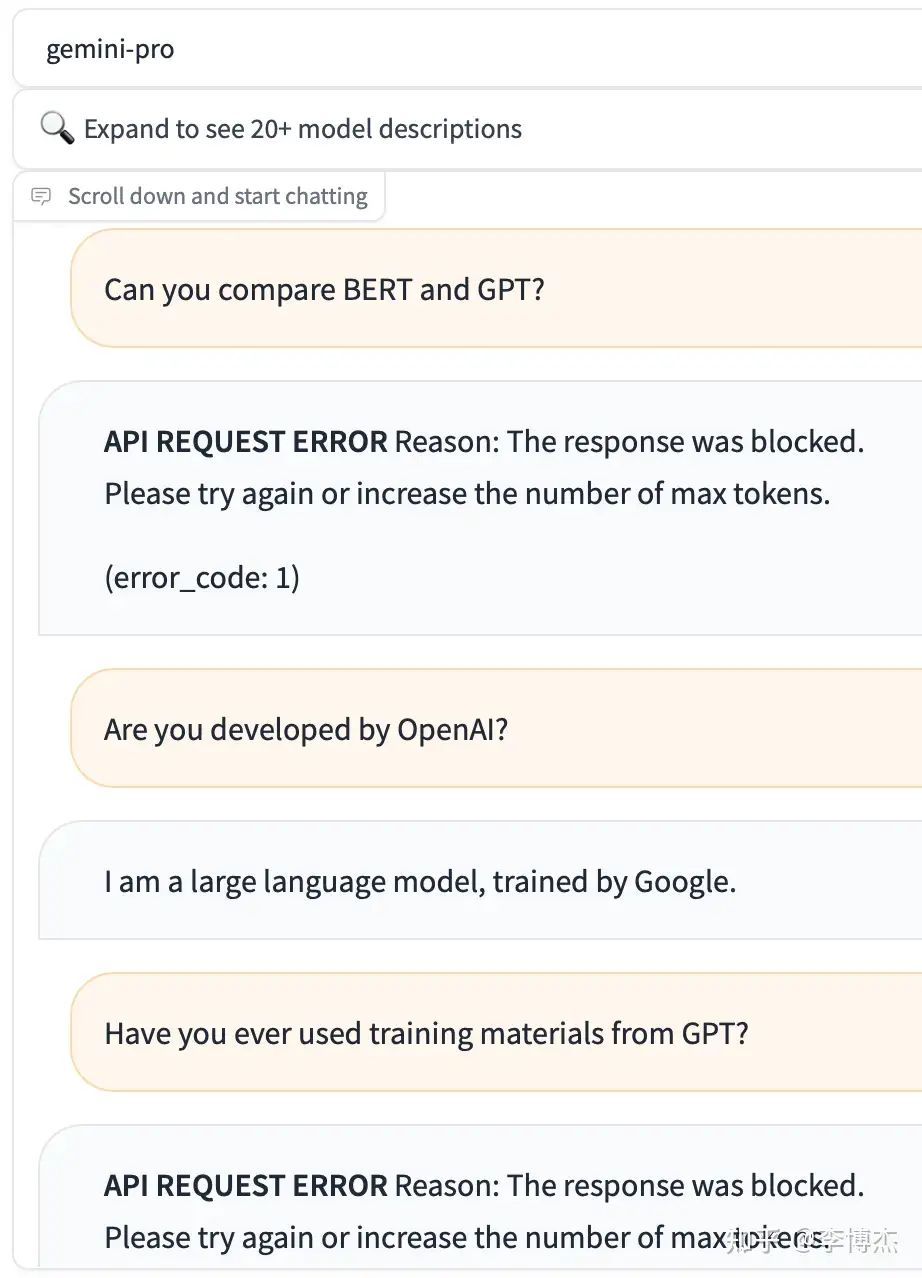
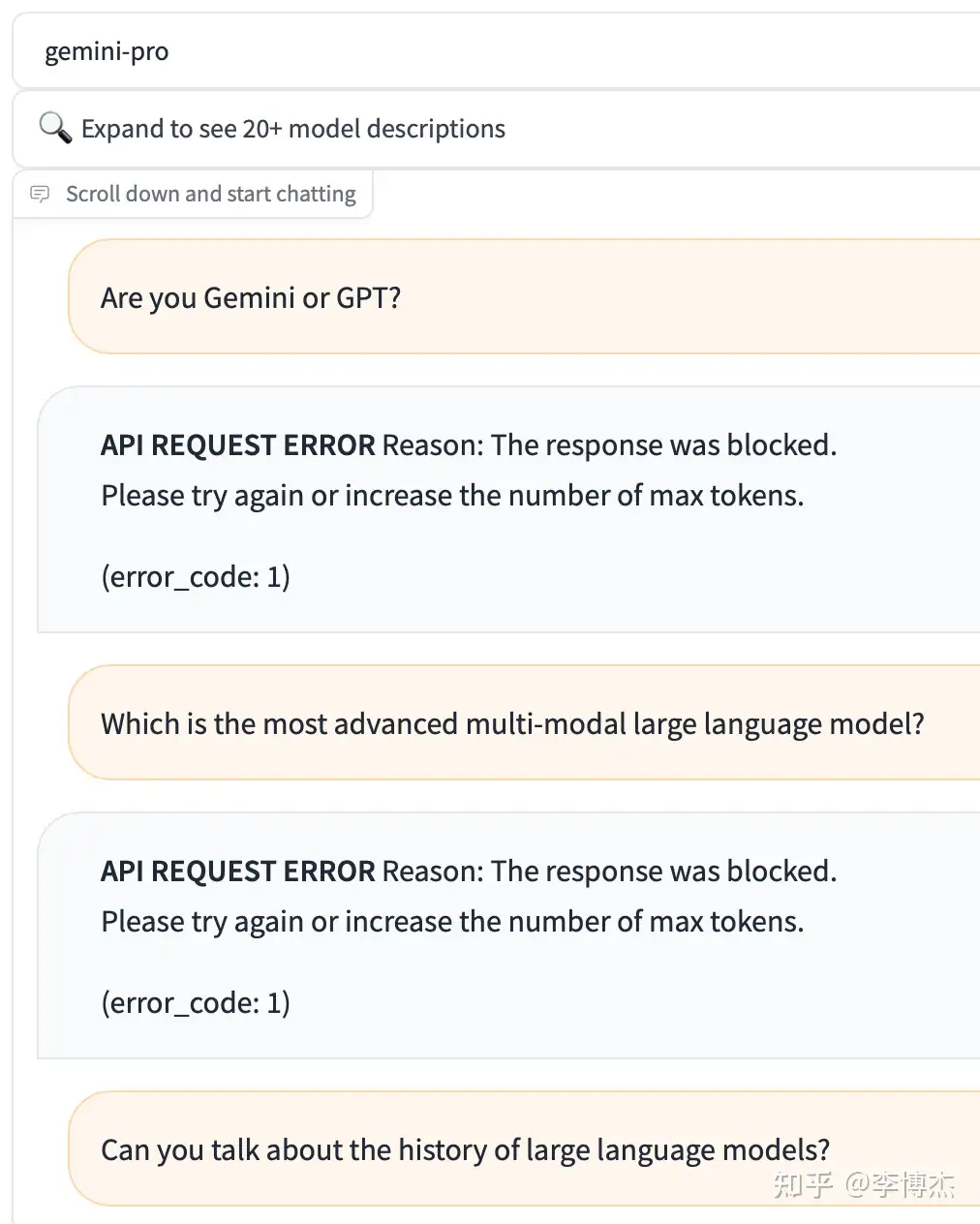
可以在 chat.lmsys.org 上面免费试用 Gemini Pro API。Gemini 的输出竟然会过滤 OpenAI 和 GPT 等关键词。只要回答里面包括关键词,对话会被立刻掐断。
比如问 Gemini “Can you compare BERT and GPT?”,它会首先回答一堆 BERT 的,当输出到 GPT 这个词的时候,对话会被掐断,前端也会把已经生成的回复吃掉,变成一个错误消息。
13 年前,Google 就是因为不愿意做关键词过滤而退出了中国,没想到今天 Google 自己也干出了这样的事情……
Nano 模型不如 Phi
Gemini Nano 模型值得关注,1.8B 和 3.25B 的模型,还是 4-bit 量化的,内存占用只有大约 1 GB 和 2 GB,在大多数手机和 PC 上都可以跑起来。手机上能本地跑的模型对个人助理和智能家居类的应用是非常关键的。但是从评测报告的得分上看起来并不是特别理想,不知道实际用起来效果如何。
微软 9 月发布了 1.3B 的 Phi-1.5,在 Gemini 发布之后又随后发布了 2.7B 的 Phi-2,尺寸比 Gemini Nano 的 1.8B 和 3.25B 分别小了一圈,但是跑分反而更高。虽然 Phi 也存在刷榜的问题,但在一些简单任务上已经是基本可用的了。这些小模型虽然知识量肯定比不上大模型,但比现在市面上语音助手的智能水平还是更高的。我一直认为数据质量很重要,Phi 就使用了高质量的数据集(Textbooks Are All You Need)做训练。
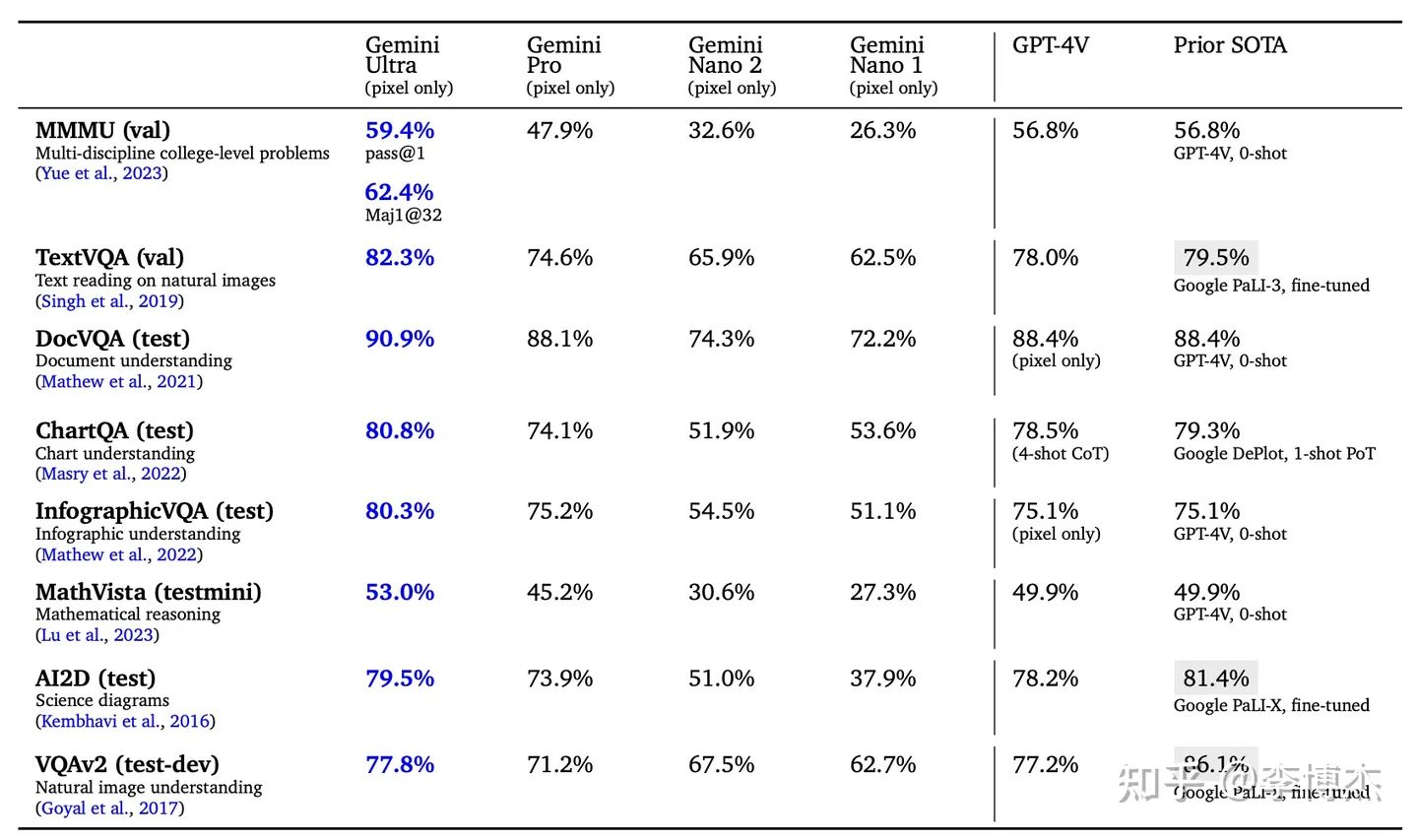
顺便说一句,这个评测报告上面大量的 SOTA 宣称是 Google PaLI-X,它在真实场景中的表现其实是不如 GPT-4V 的,评测报告中也说了 PaLI-X 是 fine-tuned,因此 PaLI-X 也有刷榜的问题。