SIGCOMM '21 Talk Transcription for 1Pipe: Scalable Total Order Communication in Data Center Networks
Bojie Li, Gefei Zuo, Wei Bai, and Lintao Zhang. 1Pipe: Scalable Total Order Communication in Data Center Networks. SIGCOMM ‘21. [Paper PDF] [Slides with audio (25 min)] [Slides with audio (12 min)]

I’m Bojie Li from Huawei. It’s my honor to speak at SIGCOMM ‘21 about 1Pipe, a scalable and efficient total order communication mechanism in data center networks.
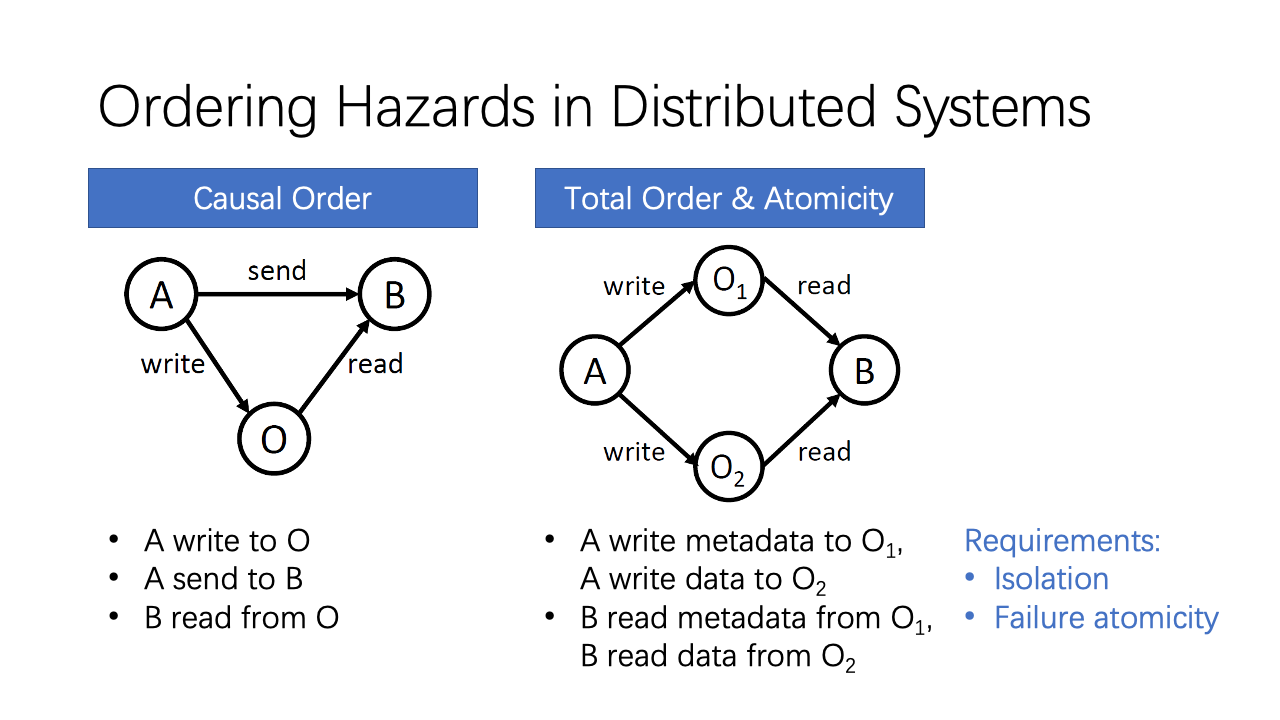
The first thing we want to define is what kind of ordering we want to provide in a distributed system.
There are two kinds of ordering anomalies in a distributed system. The first kind violates causal ordering. For example, Host 𝐴 writes data to another host 𝑂, then sends a notification to host 𝐵. When 𝐵 receives the notification, it issues a read to 𝑂, but may not get the data due to the delay of A’s write operation.
The second kind violates total ordering or atomicity. Host 𝐴 first writes to data 𝑂2 and then writes to metadata 𝑂1. Concurrently, host 𝐵 reads metadata 𝑂1 and then reads data 𝑂2. It is possible that 𝐵 reads the metadata from 𝐴 but the data is not updated yet. This is called isolation among concurrent transactions. It is also possible that one of the two write operations fail, so the metadata and data are inconsistent. This is called failure atomicity.
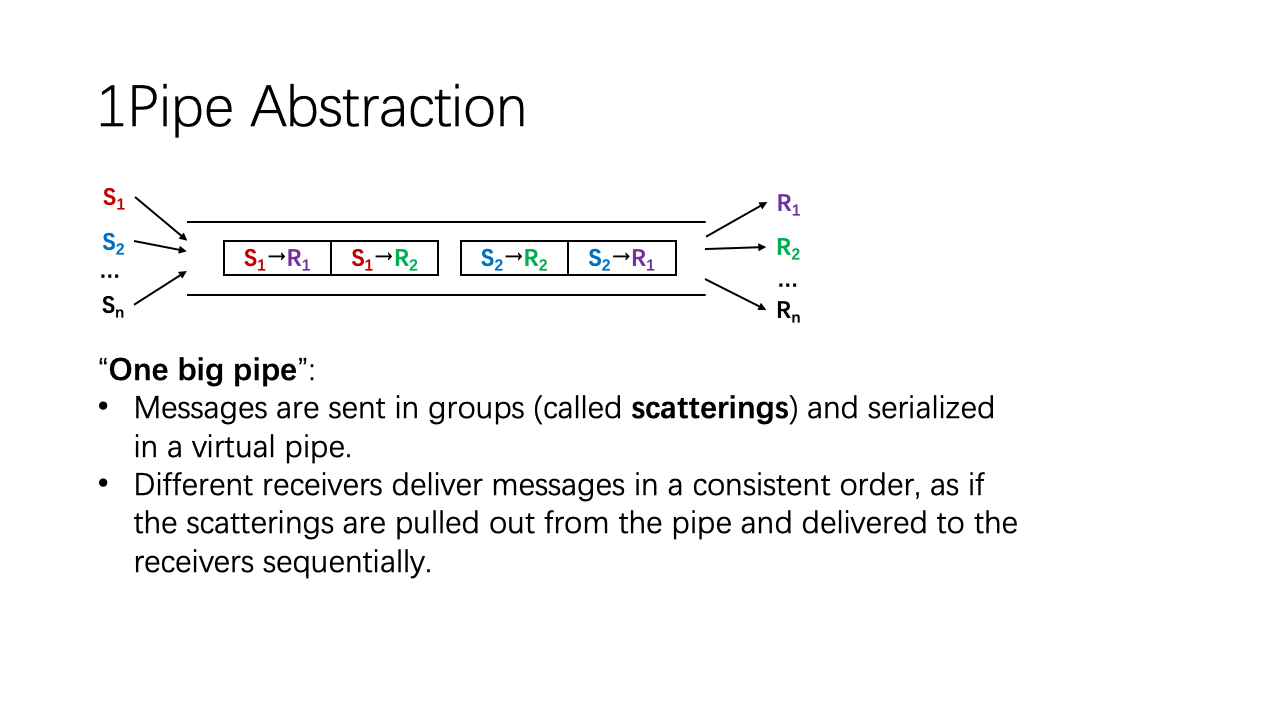
To avoid these two kinds of ordering anomalies, we propose a “one big pipe” abstraction.
First, messages are sent in groups (called scatterings) and serialized in a virtual pipe.
Second, different receivers deliver messages in a consistent order, as if the scatterings are pulled out from the pipe and delivered to the receivers sequentially.
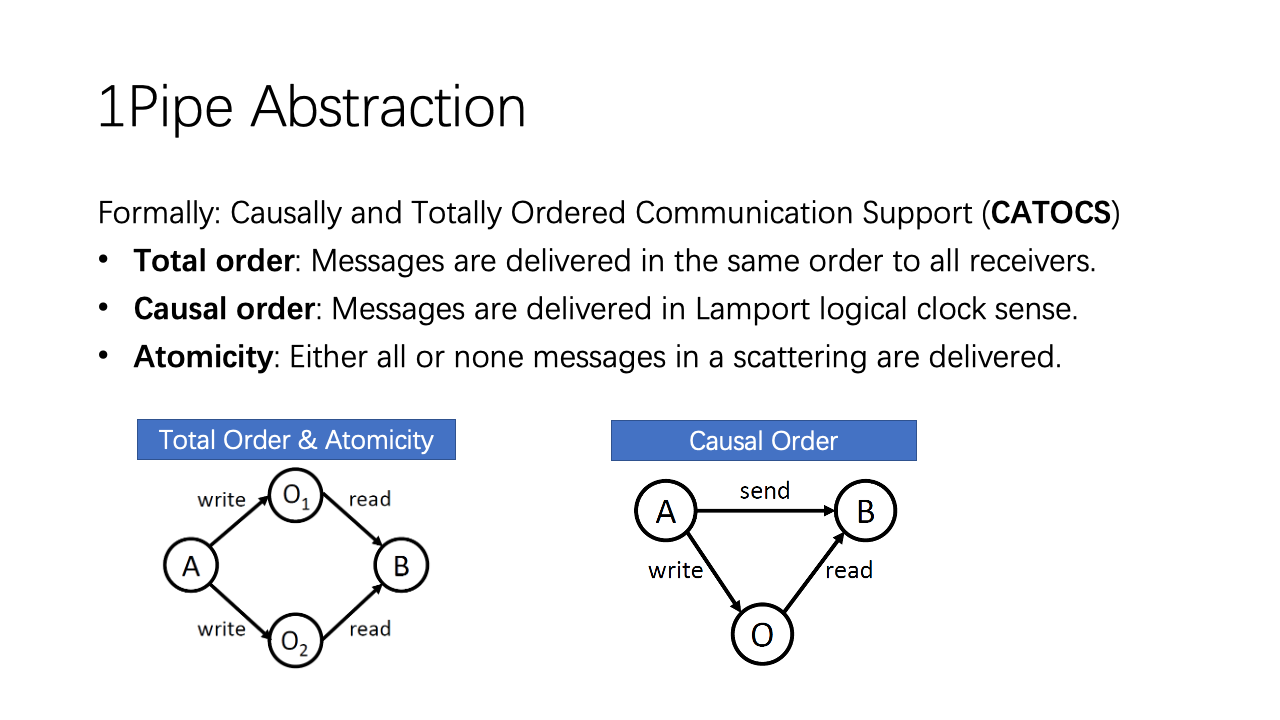
Formally, 1Pipe provides an abstraction named Causally and Totally Ordered Communication Support (CATOCS). It has three properties:
- Total order: Messages are delivered in the same order to all receivers.
- Causal order: Messages are delivered in Lamport logical clock sense.
- Atomicity: Either all or none messages in a scattering are delivered.

We must make it clear that 1Pipe only provides restricted failure atomicity. Because the seminal FLP theorem already said full failure atomicity is impossible. If Receiver 1 can fail permanently at any time, how can Receiver 2 know whether it has delivered M or not?
Replicating every message would introduce a too high overhead. Fortunately, we can apply the design principle of optimizing for the normal case, because data center is mostly reliable. We have a mechanism to invoke the application to handle the failures.

Now we consider the core design of 1Pipe: how to achieve total order.
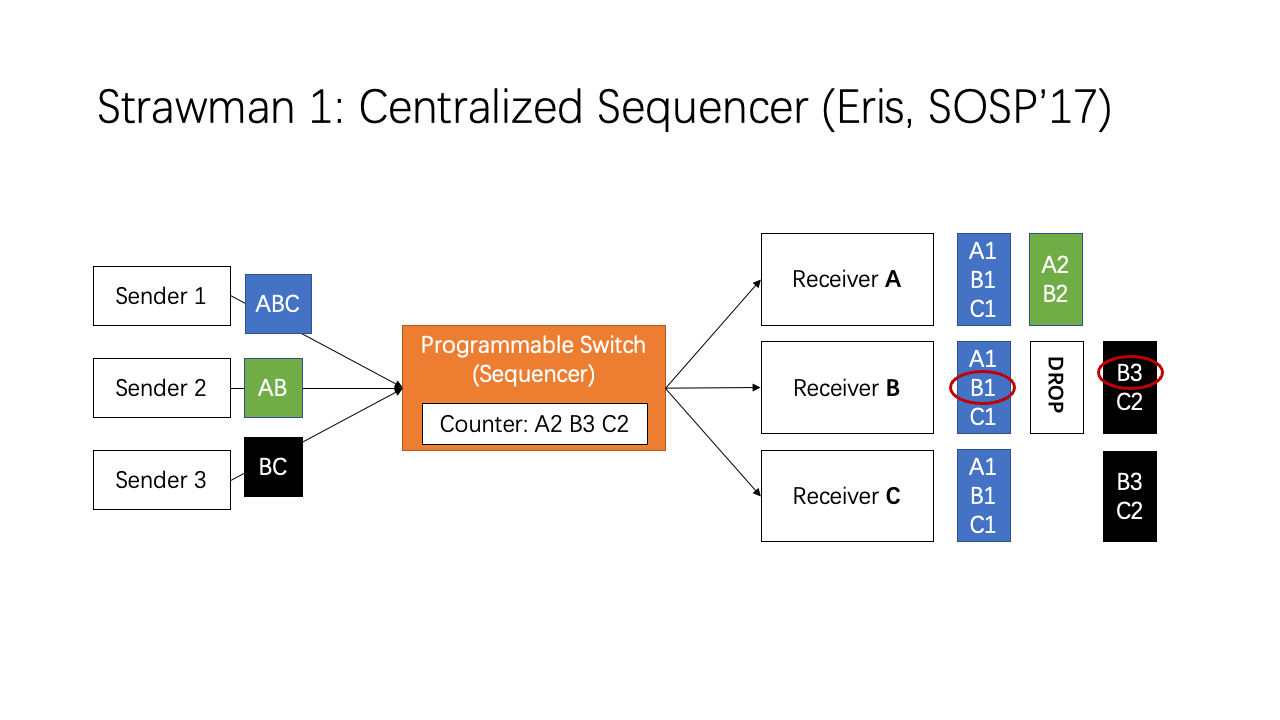
The first strawman is the approach of Eris. Eris uses a programmable switch as a centralized sequencer, which keeps a counter for each receiver. When a receiver detects a gap in its sequence number, as shown in the red circles, the receiver knows there is a lost message, the failure coordinator will use a traditional consensus algorithm to achieve consensus among replicas. However, the major problem is that the switch becomes a centralized bottleneck.

Now we come to the second strawman. We synchronize physical time on senders. The messages are attached with physical timestamps. When a receiver receives a message, it first puts the message into receive buffer. The receiver maintains a timestamp for each sender, and computes the minimum timestamp of all senders. If the minimum timestamp is greater or equal than the timestamp of some message, then the receiver can safely deliver this message.
This approach also has several drawbacks.
- Each message needs to broadcast to all receivers (including those not needed).
- Periodic beacons needed for an idle pair of receivers (quadratic number of beacons, not scalable).
- Cannot detect packet loss and failures.
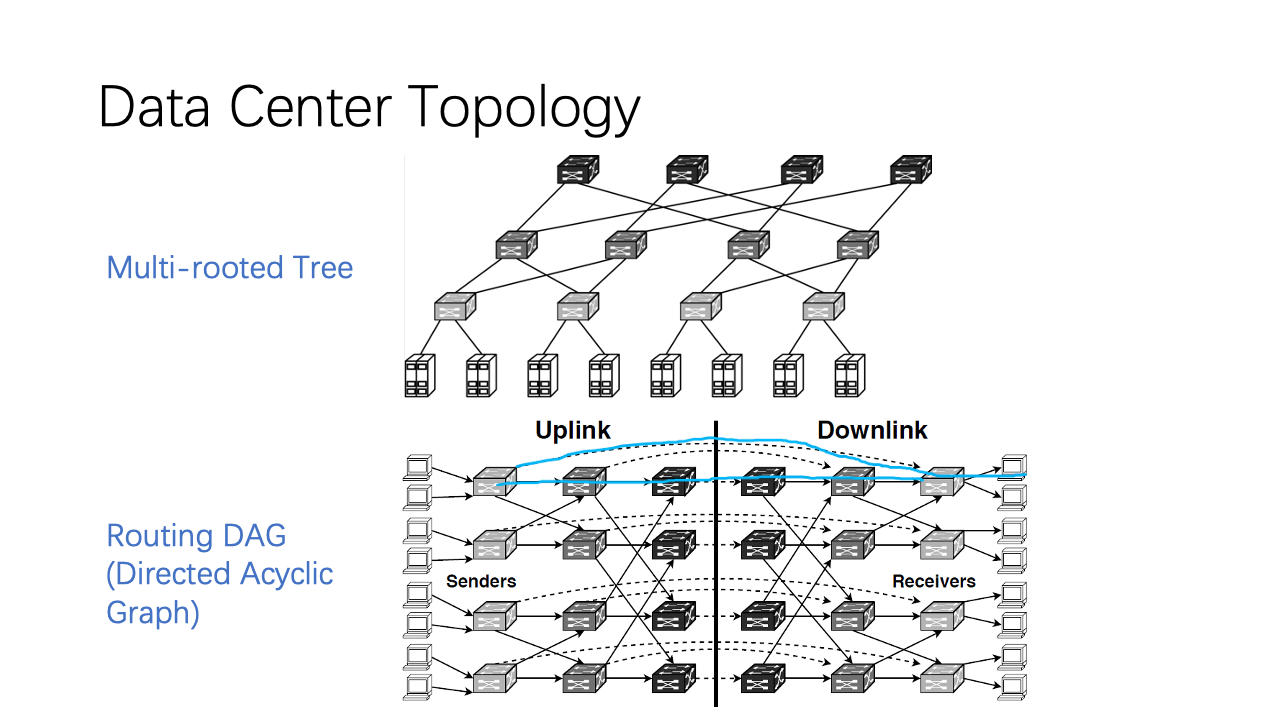
Now we design 1Pipe for the data centers. A typical data center has multi-rooted tree topology. Each host has two roles, both sender and receiver. The routing graph between sender and receiver is a directed acyclic graph. In this directed acyclic graph, each switch and host is separated into two parts, and the dashed arrows indicate a loopback on the network switch. For example, if a host wants to communicate with another host in the same rack, it goes through this dashed arrow. If a host wants to communicate a host in another cluster, it needs to go through leaf, spine, and core switches.
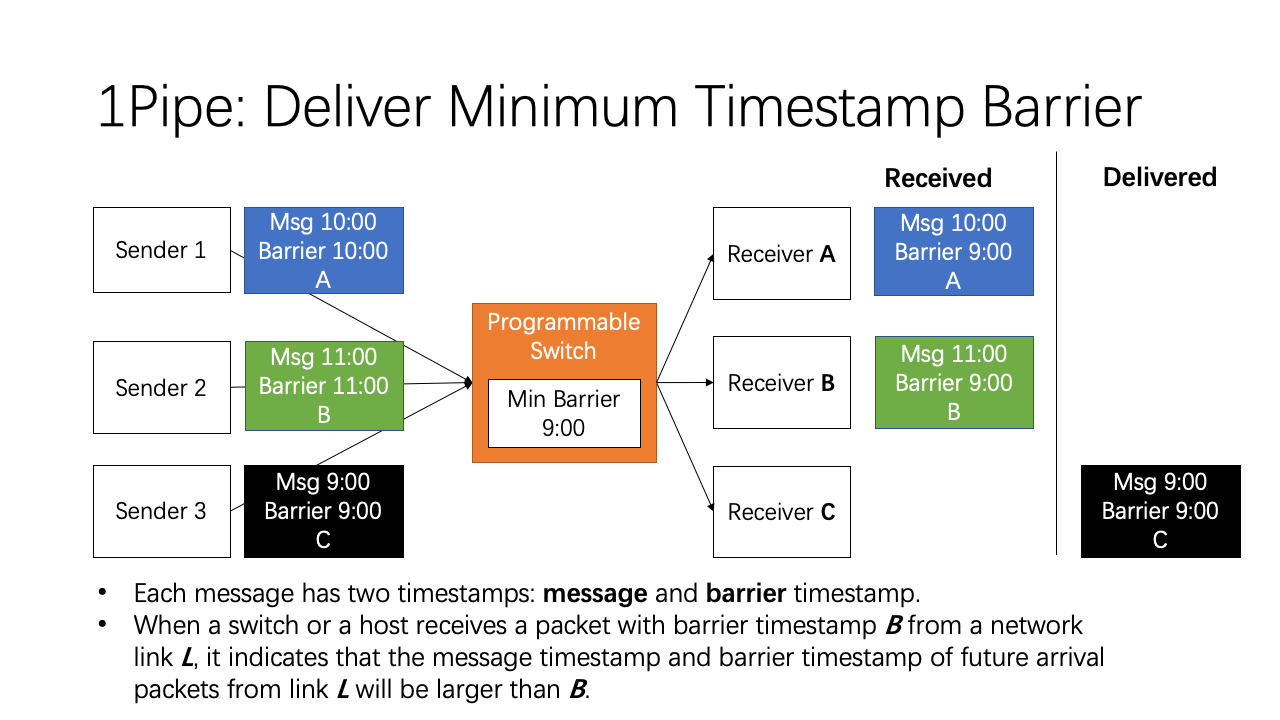
The key design of 1Pipe is similar to the last strawman, which synchronizes the physical clocks on senders, aggregates the minimum timestamp on receivers, and delivers the messages in increasing timestamp order on receivers. In the last strawman, each sender needs to send beacon to each receiver. To solve this scalability problem, we use a programmable switch to aggregate the minimum timestamp of senders, and broadcast the minimum timestamp to all receivers. Each packet has two timestamps, a message timestamp and a barrier timestamp. The message timestamp does not change during forwarding, but the barrier timestamp is changed during forwarding. When a switch or a host receives a packet with some barrier timestamp from a network link, it indicates that the message timestamp and barrier timestamp of all future arrival packets from this link will be larger than the barrier timestamp.
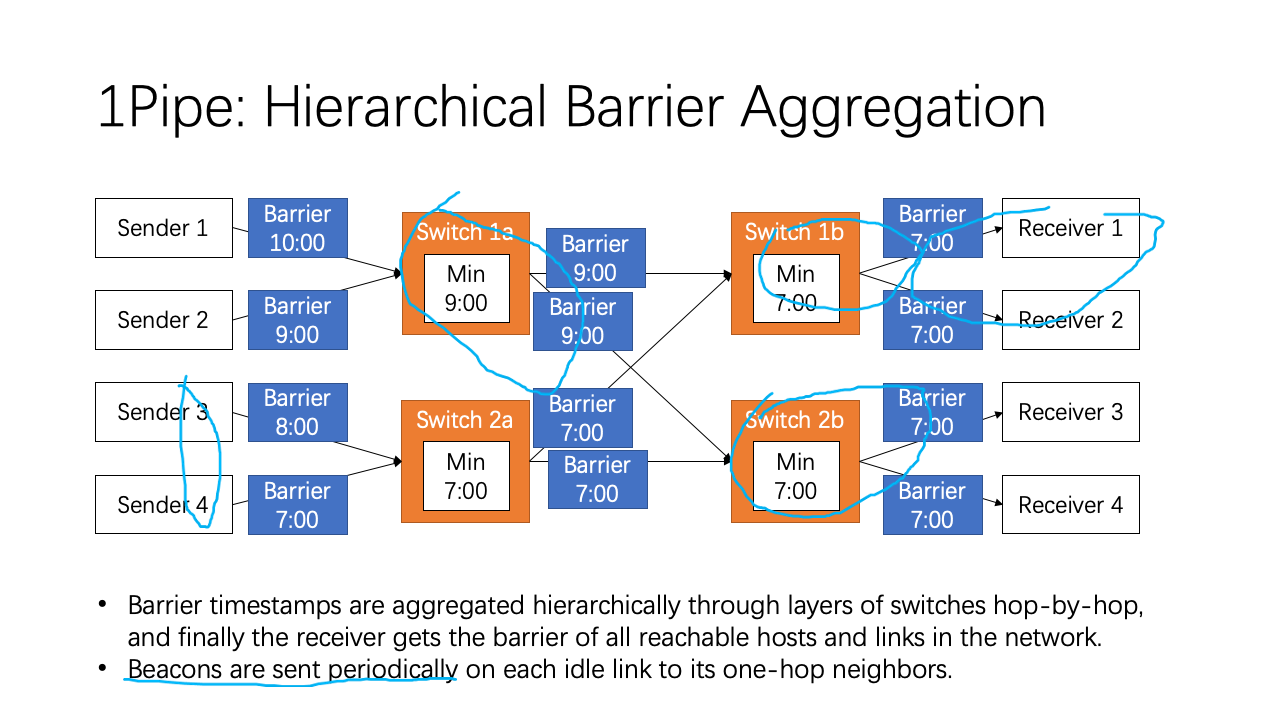
Now let’s consider a directed acyclic graph of network switches. We can hierarchically aggregate the barrier timestamps through layers of switches hop-by-hop. For example, the switch 1a computes the minimum barrier of sender 1 and 2, and broadcasts the minimum barrier to switch 1b and switch 2b. Switch 1b and 2b also receives the minimum barrier from sender 3 and 4. So switch 1b and 2b gets the barrier of all 4 senders. In this way, each receiver gets the barrier of all reachable hosts and links in the network. We recall the barrier property that on each network link, either between host and switch or between two switches, the barrier timestamp is the minimum possible future data timestamp on this link. So, a receiver can deliver message in receive buffer when it receives a barrier timestamp higher or equal to the message timestamp.
Finally, if some network links are idle, it will stall the entire network. So, beacons are sent periodically on each idle link to its one-hop neighbors. Okay, this is how 1Pipe works.
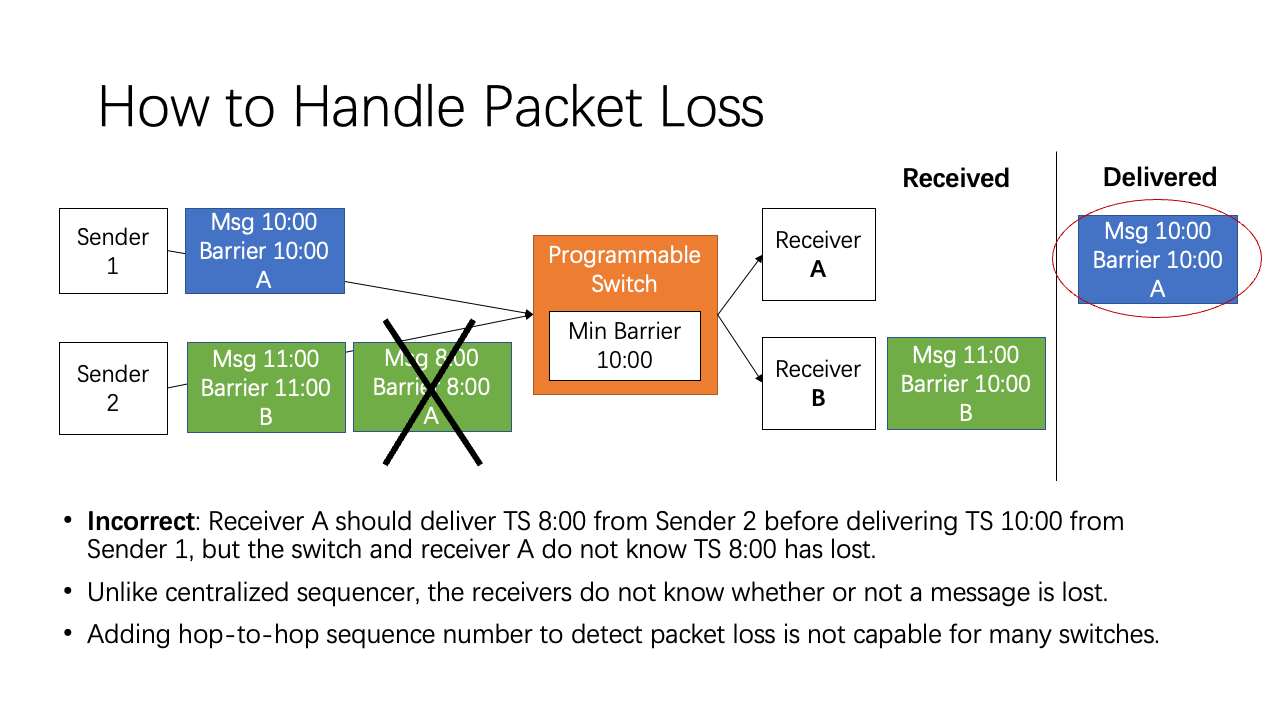
Now let’s consider packet losses. Unlike centralized sequencer, because the timestamps are not consecutive, the receivers do not know whether or not a message is lost.
For example, the packet from sender 2 to receiver A with timestamp 8:00 is lost, but neither the switch nor receiver A know the packet has lost. Then after the packets at 10:00 and 11:00 reach the programmable switch, receiver A’s barrier timestamp would be 10:00, and deliver the blue packet at 10:00. The total ordering property requires the messages to be delivered in increasing timestamp order, but receiver A has now delivered an out-of-order packet.
A straightforward solution is to add hop-to-hop sequence number to detect packet loss. However, this is not capable for many commodity switches.

Unfortunately, our solution to recover lost packets and failures require an extra round-trip time. So we provide two kinds of services: a best effort service that provides at-most-once delivery, and a reliable service that provides exactly once delivery at the cost of an extra round-trip time.
Why do we need a best-effort service? This is because some use cases of 1Pipe only need ordering but do not need reliability. For example, a read-only transaction can be safely retried if some of the messages are lost.

Reliable 1Pipe achieves reliability with a two-phase commit approach. The sender first sends a prepare message to the receiver. The prepare message contains a message timestamp which is the wall clock time of the sender. The receiver puts the message into the receive buffer. Then the receiver responds with an ACK message. The Prepare and ACK messages do not need ordered delivery.
When a sender collects all ACKs below or equal to timestamp T, it sends a commit message to the neighbor switch. This commit message means to deliver all messages below or equal to the commit timestamp. Notice that the commit message no longer carry two timestamps. It does not need the message timestamp. Only the barrier timestamp is needed, and it is now renamed as commit timestamp.
The switches aggregates minimum timestamp of commit messages as in best-effort 1Pipe. The commit timestamp still has the monotonic property. When a receiver receives a commit timestamp, it delivers buffered messages below or equal to the commit timestamp.
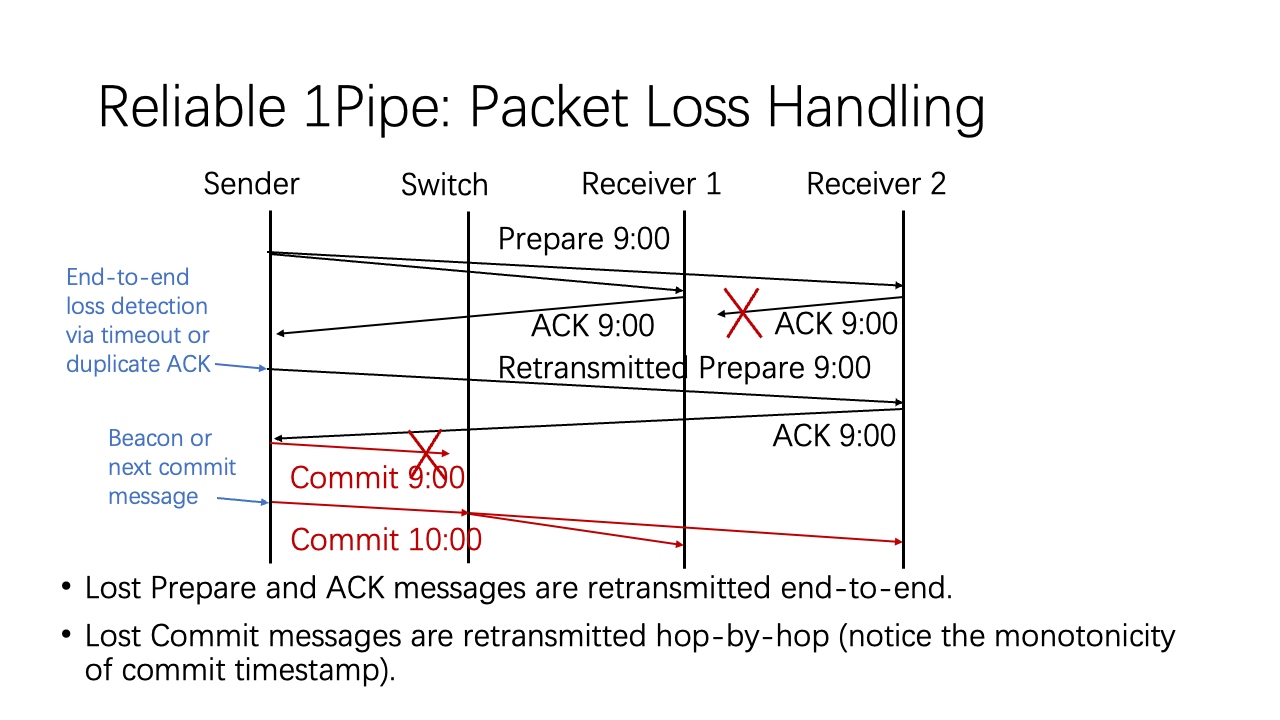
Now let’s see how reliable 1Pipe handles lost packets. In the first example, the ACK packet of a Prepare message is lost. The sender can detect this lost packet according to an end-to-end transport mechanisms such as timeout or duplicate ACK. After the retransmitting the prepare message and the ACK message is successfully received by the sender, the sender can send out the commit message.
In the second example, the commit message is lost. Actually we do not need to retransmit commit messages. Because commit timestamp is monotonic, committing timestamp 10:00 implies committing timestamp 9:00. Even if there are no other messages to commit, we have periodic beacons on each network link, so the commit timestamp will be automatically retransmitted.
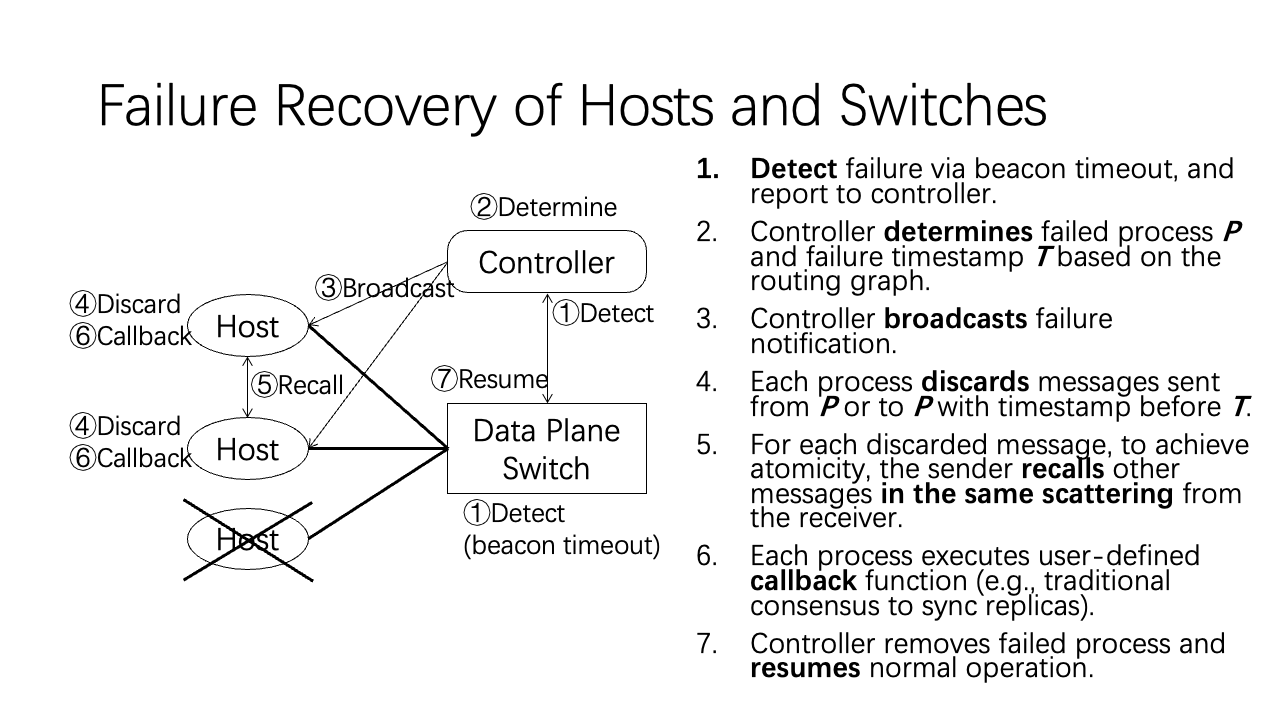
After handling packet loss, now we come to failure recovery of hosts and switches.

Now we consider the recovery of simultaneous failures. For example, in the figure, the host and switch 1 fails simultaneously. Failure recovery is directed by the controller. The controller needs to determine which components have failed and when each component fails. The former question is easy to answer. But the latter question is hard to answer. Please see the paper for more details.

As we have already discussed, failure recovery has its limitations. If receiver A crashes at some unknown time, we do not know the last timestamp A has delivered, so the other receiver B of the same scattering does not know whether A has delivered TS 9:00.
We only ensure atomicity in fail-recover model: when receiver A recovers from the failure, it communicates with the controller to determine which messages in the receive buffer should be delivered.

Next, we come to the implementation of 1Pipe.
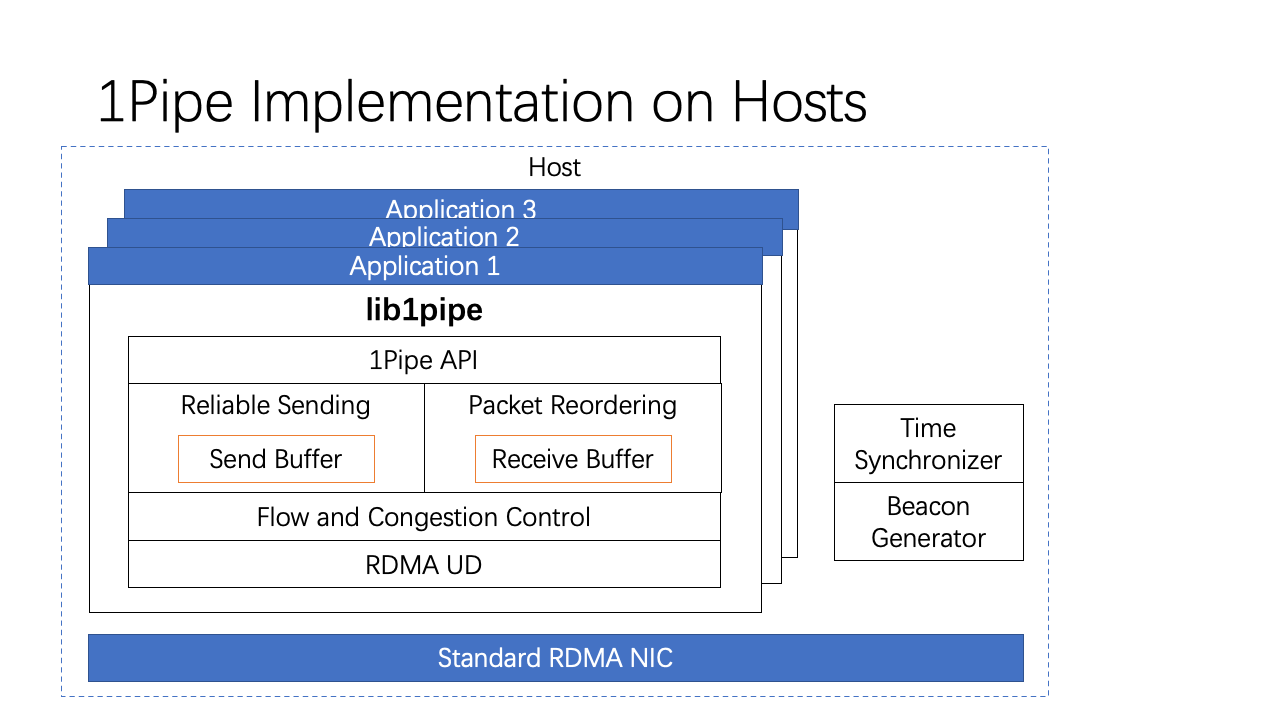
We implement 1Pipe using RDMA Unreliable Datagram. This is because if we use RDMA reliable connection, each QP will buffer several messages, and we cannot ensure the ordering among these messages on the network link. Ideally, we would like to use a SmartNIC to assign timestamps at the egress of the NIC. But we do not have access to such a SmartNIC, so we used a software approach instead. The transport is implemented in software. 1Pipe has a polling thread per host to synchronize the clock and generate periodic beacons to the top-of-rack switch.
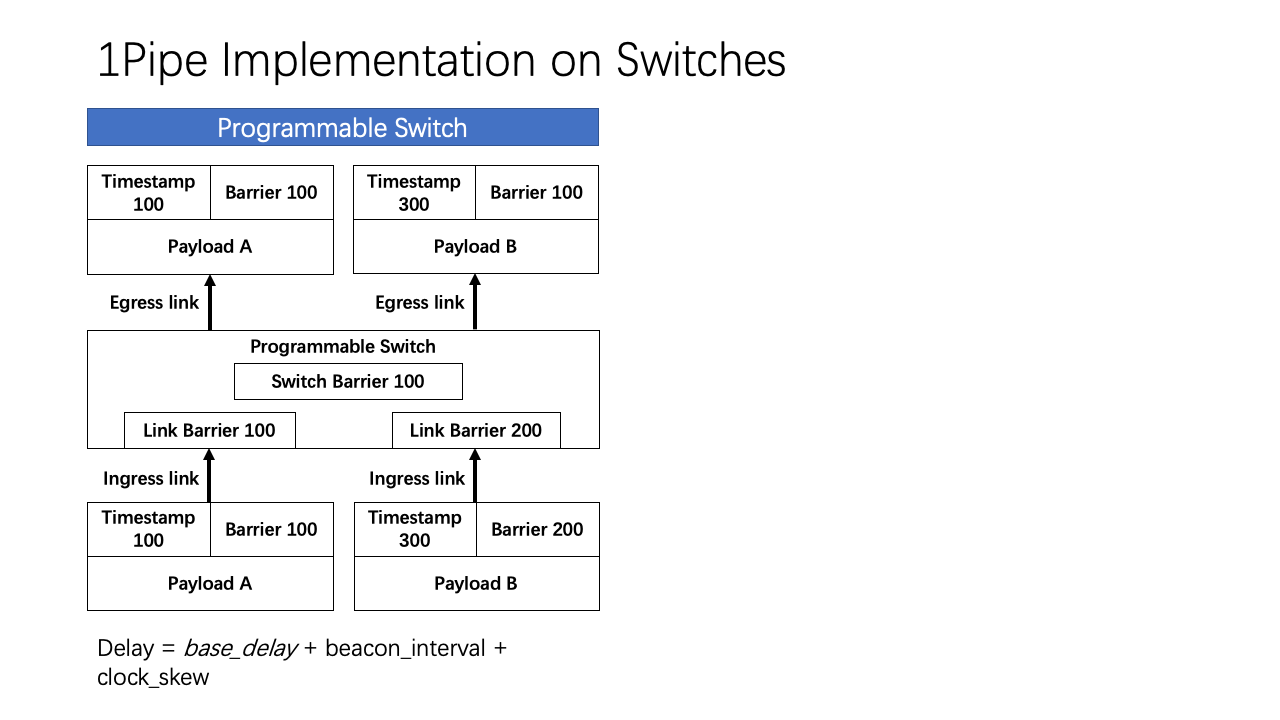
For implementation on network switches, we consider three types of network switches with different programmability. Using a programmable switch, the switch data plane can aggregate barrier timestamps in the header of each packet. Because a switch has multiple input ports, the switch actually uses a binary tree of registers in multiple stages to compute the minimum barrier of all input ports. The forwarding delay of programmable switch is base delay plus beacon interval plus skew in clock synchronization.
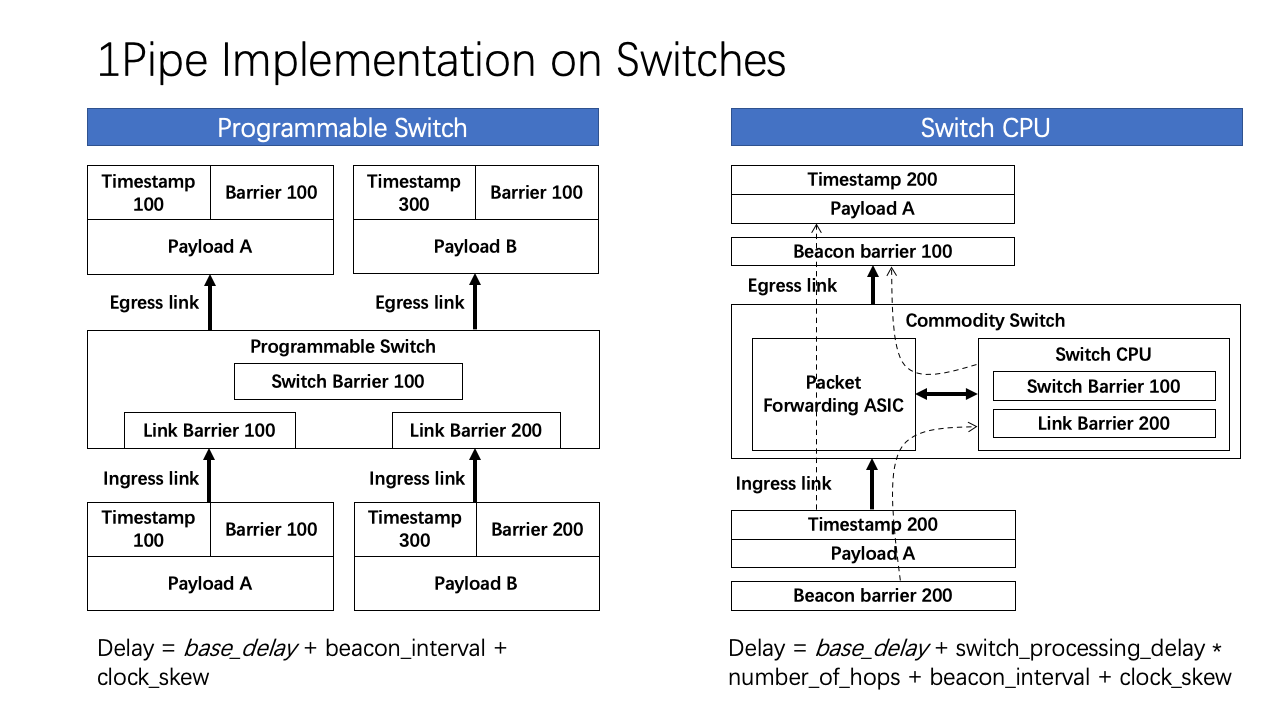
For a commodity switch without a programmable switching chip, for example Broadcom switching chips, we implement in-network processing on the switch CPU. Although it cannot process packets in data plane, they have a CPU to process control-plane packets, analogous to directly connecting a server to a port of the switch. Compared to a typical server, the switch CPU is typically less powerful and has lower bandwidth. Because the switch CPU cannot process every packet, data packets are forwarded by the switching chip directly. The CPU sends beacons periodically on each output link, regardless of whether the link is idle or busy.
Compared with the programmable chip, switch CPU slacks the barriers because 1) CPU processing has
delay and 2) the barriers are updated by periodical beacons instead of by every packet.
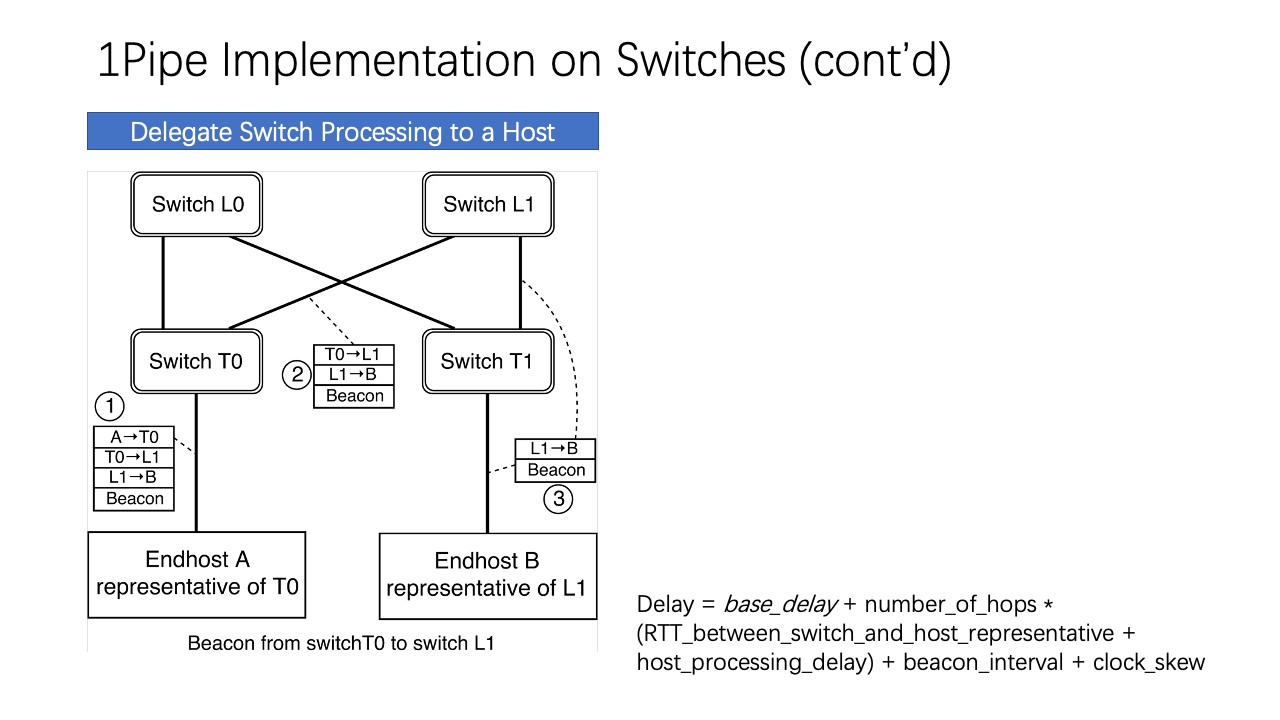
If the switch vendor does not expose access interfaces to switch CPUs, we can offload the beacon processing to end hosts. The challenge is to maintain the FIFO property on network links, i.e., beacons with barrier timestamps on a network link must pass through the link. This is a requirement of best effort 1Pipe, but not reliable 1Pipe. To this end, we designate an end-host representative for each network switch. If the routing path between two representative hosts does not go through the link between the switches, beacon packets needs to detour by using source routing.

Now, the evaluation.
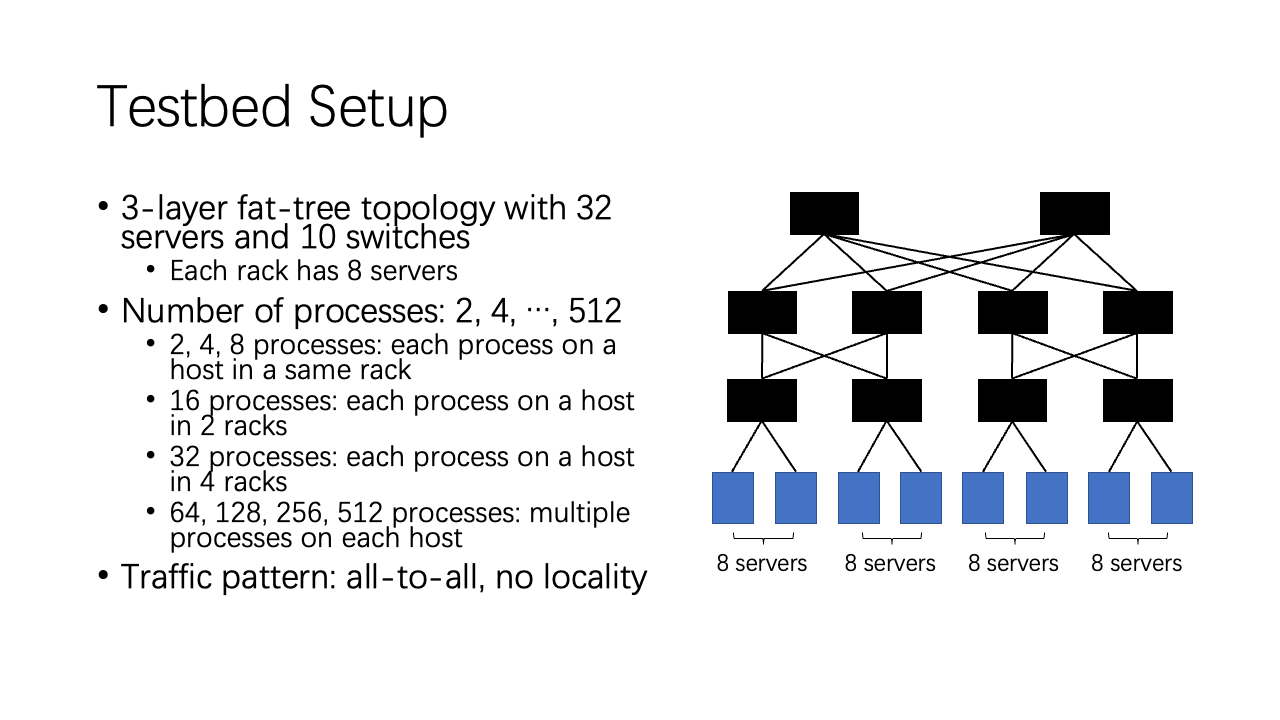
We evaluate 1Pipe in a 3-layer fat-tree topology with 32 servers and 10 switches. With a small number of processes, they are on different hosts of a same rack. With a large number of processes, they are evenly spread on all hosts. We use all-to-all traffic pattern.
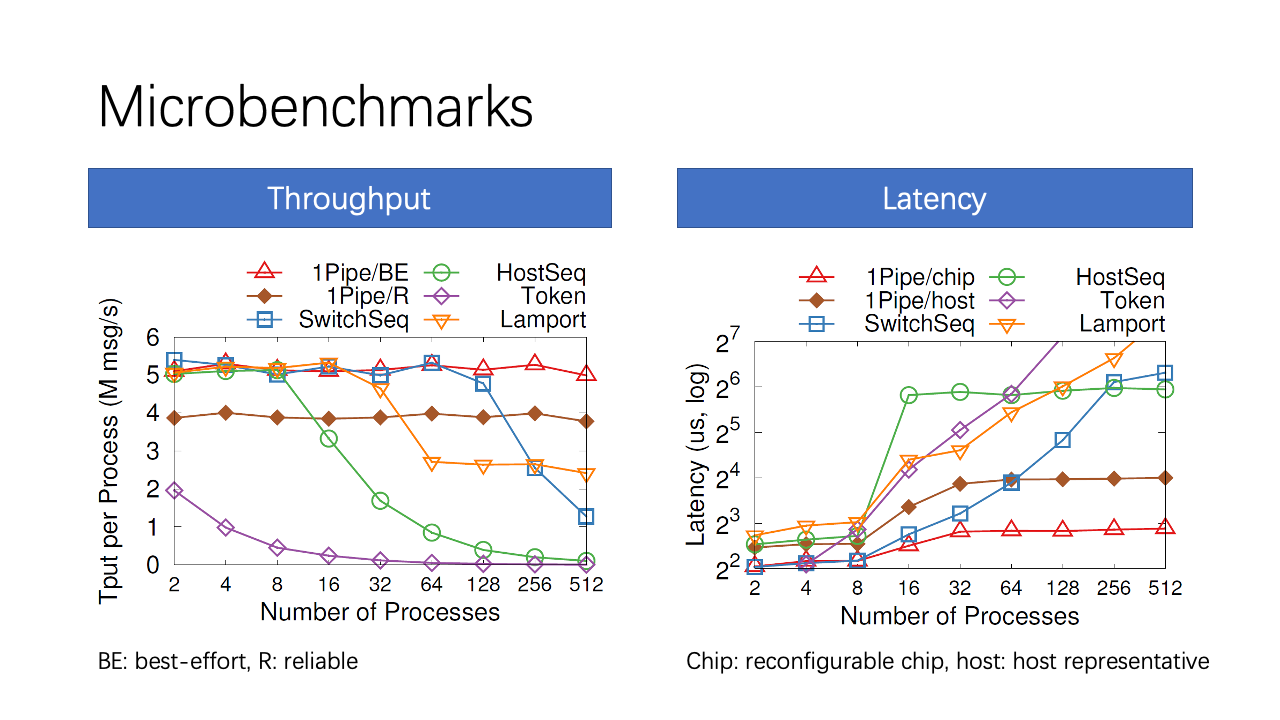
Now we compare 1Pipe with other total-order broadcast algorithms. 1Pipe scales linearly to 512 processes, achieving 5M messages per second per process (i.e., 80M msg/s per host). The throughput of 1Pipe is limited by CPU processing and RDMA messaging rate. Reliable 1Pipe has 25% lower throughput than best effort 1Pipe due to two-phase commit overhead.
In contrast, if we use switch or host as a sequencer, the sequencer is a central bottleneck and introduces extra network delays to detour packets. The latency soars when throughput of sequencer saturates and congestion appears.
Best effort 1Pipe with reconfigurable chip delivers the lowest latency overhead compared to the unordered baseline. The average overhead (1~2𝜇s) is almost constant with different number of network layers and processes. End host representatives introduce extra forwarding delay from the switch to the end host. Reliable 1Pipe adds an RTT to Best effort 1Pipe. For different number of processes, the RTT and host forwarding delay are proportional to network hop count.

The CPU overhead of 1Pipe has two parts: reordering at receivers and beacon processing at switches. Processing beacons needs one CPU core per server. For reordering at receivers, the message delivery throughput degrades slightly with a higher delivery latency.
The network bandwidth overhead of 1Pipe is mainly packet header overhead and beacon overhead. The packet header overhead is 24 bytes per packet. Beacons only require 3 in a thousand bandwidth.
Finally there is a memory overhead for send and receive buffer. As the Figure shows, the send and receive buffer size increases linearly with latency, but only takes a few megabytes.
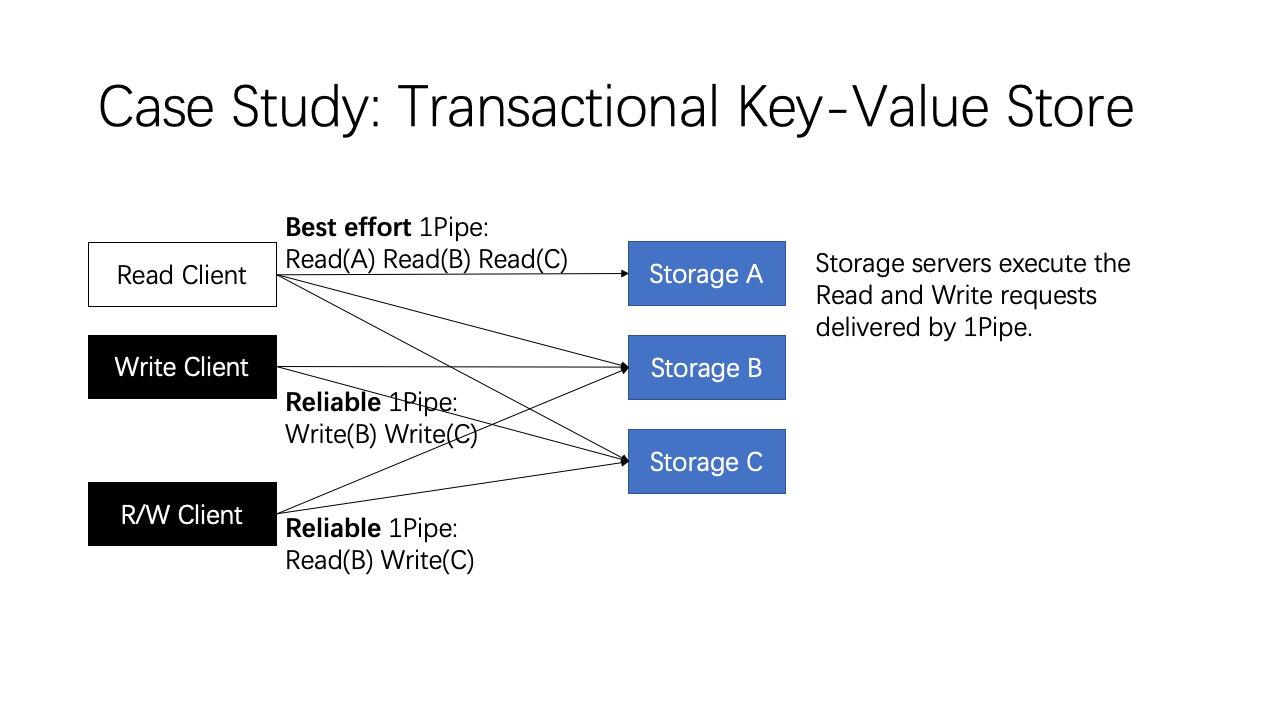
The first case study is a transactional key-value store.
For read-only transactions, we use best effort 1Pipe because it does not have any side effect. If any of the Read request fails, the client can simply retry the request. This is why we design best effort 1Pipe. Transactions including at least write operation needs to use reliable 1Pipe to ensure atomicity. In normal cases, the transaction is completed in one RTT.
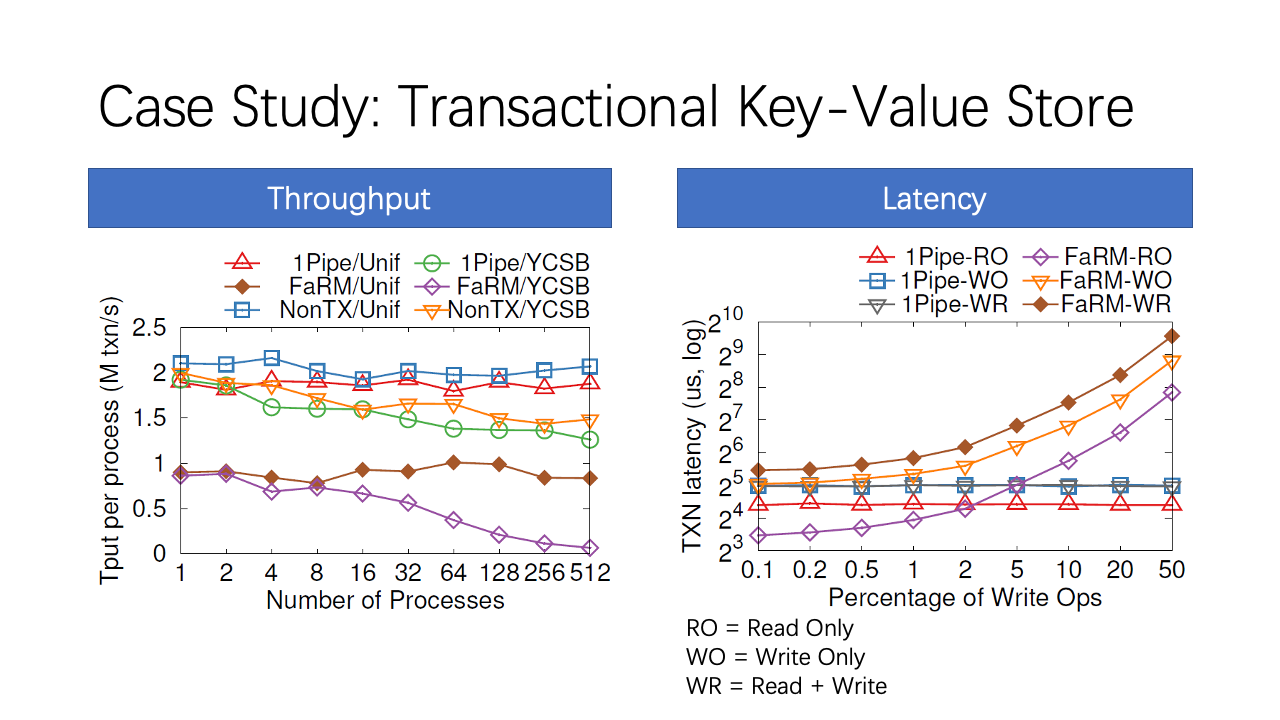
In both uniform and YCSB distribution, 1Pipe delivers scalable throughput, which is 90% of a non-transactional key-value store. As number of processes increase, YCSB scales not as linearly as uniform, because contention on hot keys lead to load imbalance of different servers.
The latency of 1Pipe is almost constant because servers process read and write ops on a same key in order. Write-only and Read-Write transactions use reliable 1Pipe, which is slower than read-only transactions that uses best effort 1Pipe. With high write percentage, FaRM latency skyrockets due to lock contention on hot keys and transaction aborts.
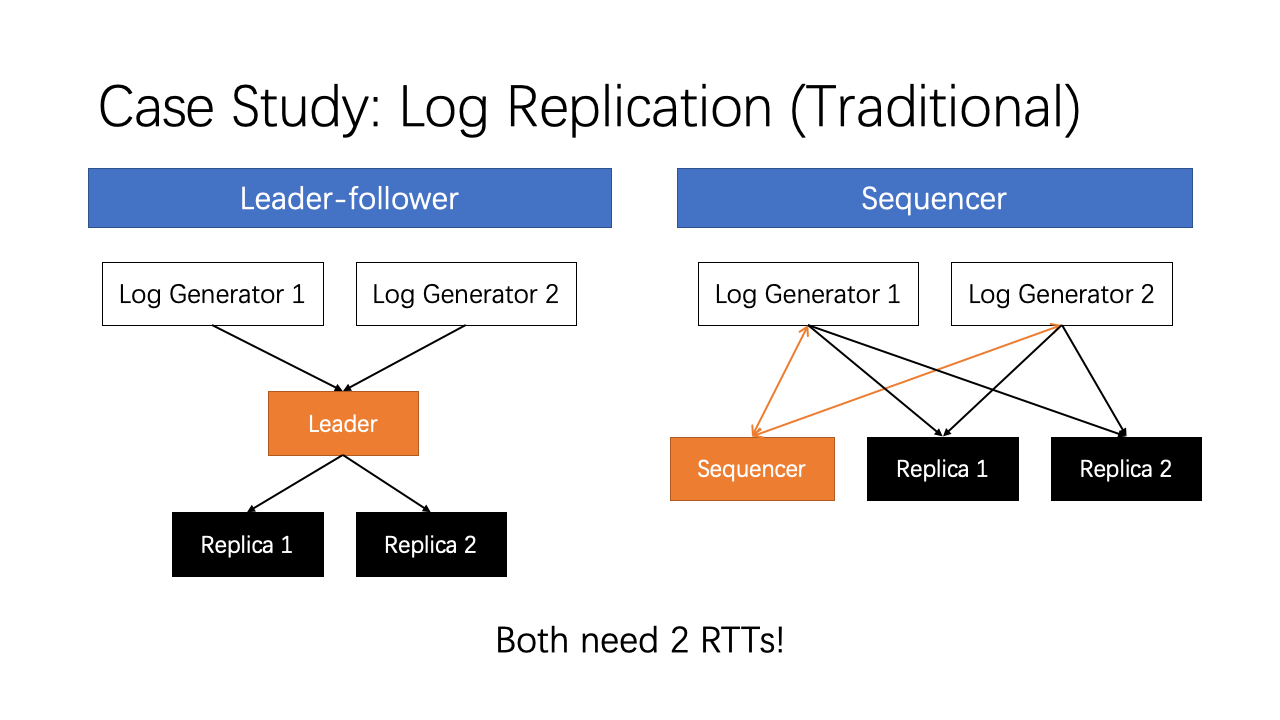
The second case is log replication. Traditionally we have two ways for log replication. The leader-follower approach first replicates data to a leader node, then the leader node replicates to several replica nodes. The sequencer approach first obtains a sequence number from a sequencer, then replicates to all replicas directly. All replicas order requests according to the sequence number. Both methods need two RTTs for replication.
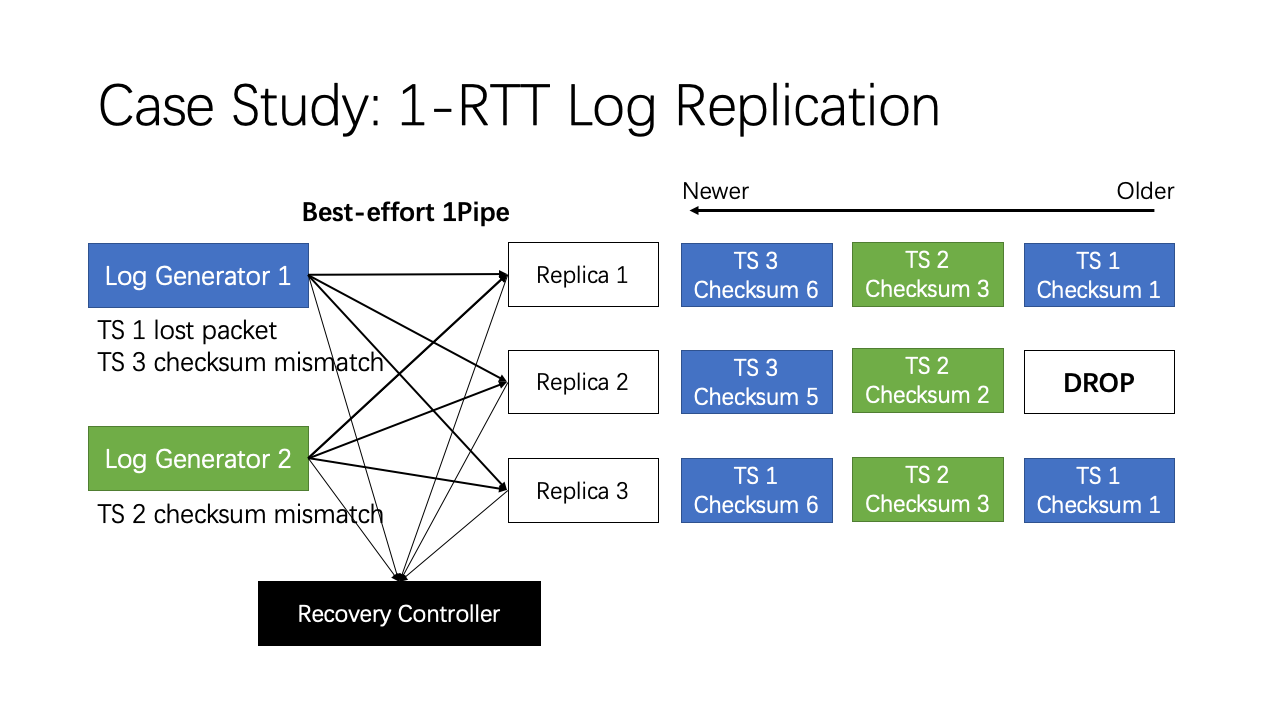
Using 1Pipe, log replication can be achieved with only 1 RTT. This is because 1Pipe removes the need of sequencer in the traditional approach. We use best effort 1Pipe to achieve minimum latency, and let the sender detect packet loss. Here is how we do. Each replica maintains a checksum, which is the sum of all timestamps the replica has received. If checksum match, then all replicas have received the log entry in a consistent order. If the checksums do not match, then at least one log entry is lost. The log generator notifies the controller when there is any checksum mismatch, and the controller uses a traditional consensus algorithm to synchronize the log entries on replicas. After that, the replicas resume accepting new logs.
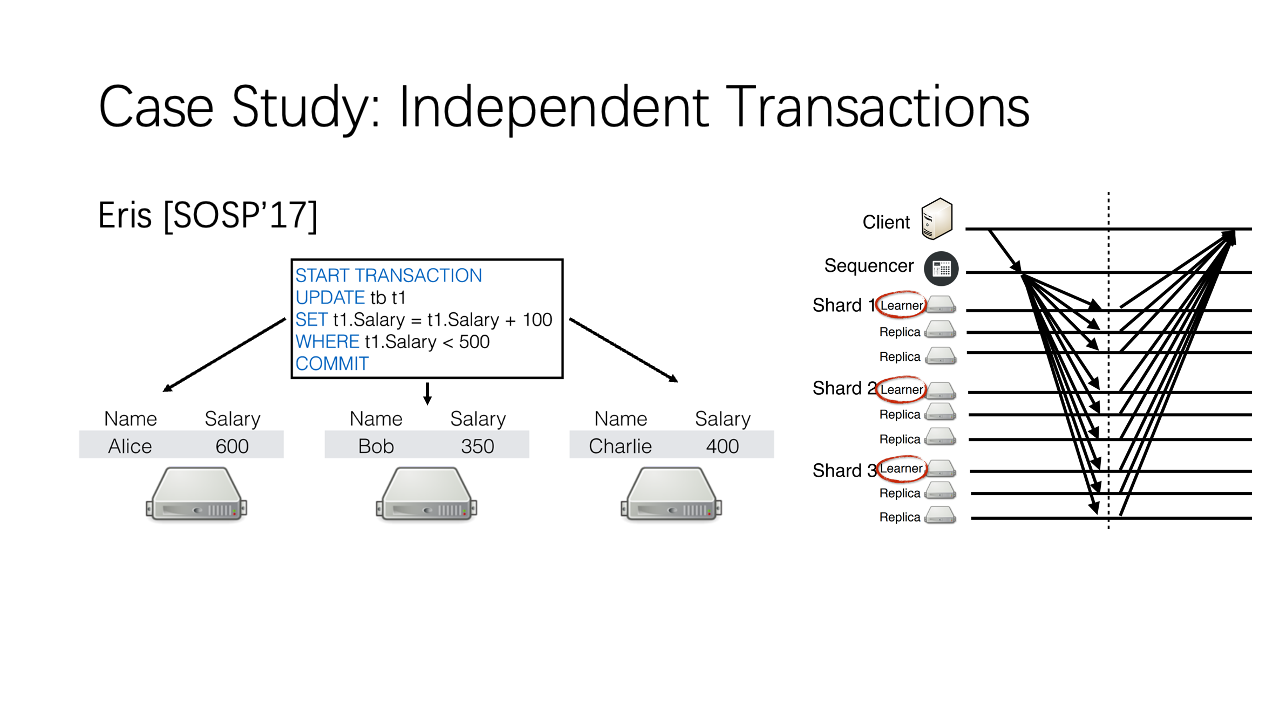
The last case study is independent transactions, which involve multiple hosts but the input of each host does not depend on the output of other hosts. The two most frequent transactions in TPC-C benchmark (New-Order and Payment) are independent transactions. An independent transaction involves multiple shards, and each shard have multiple replicas. So each packet in a transaction would be multicast to a different set of receivers. Eris multicasts the message from the client to all replicas of all related shards.
Similar to Eris, we use reliable 1Pipe to send commands in an independent transaction to all replicas in relevant shards. In normal cases, the transaction can be completed in one round-trip, similar to Eris. But remember that we have better scalability.
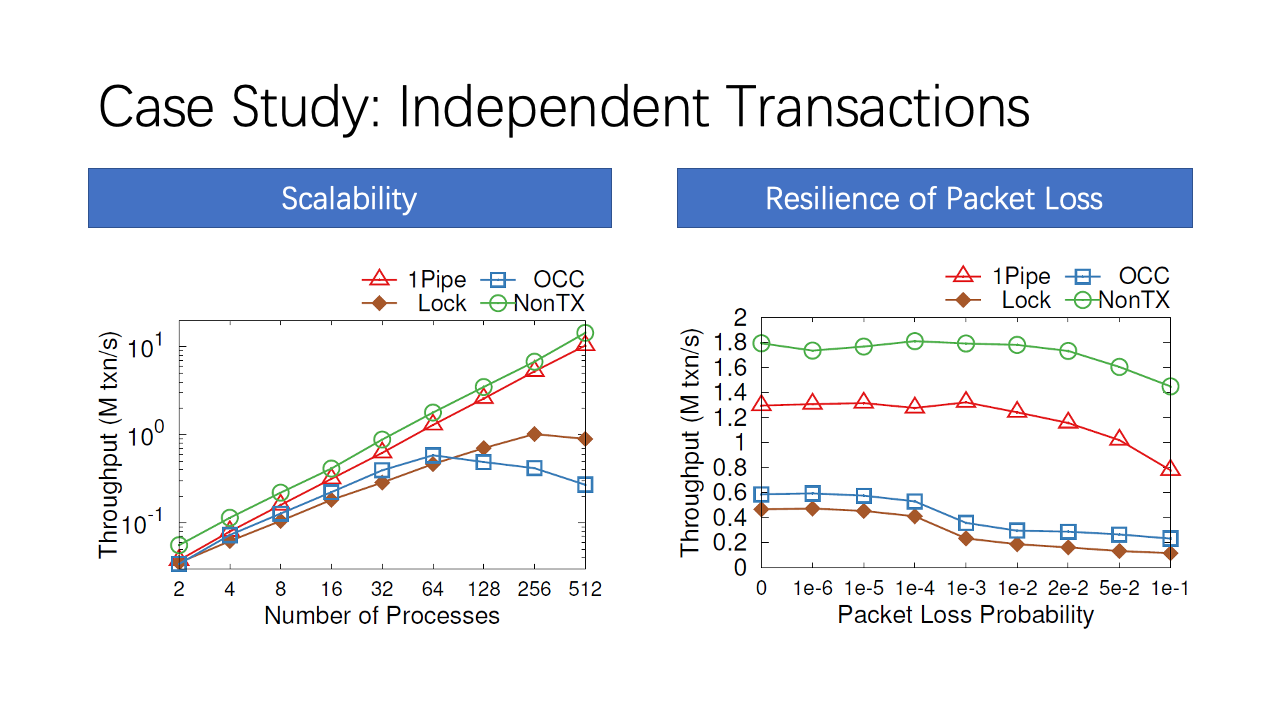
We benchmark New-Order and Payment transactions in TPC-C workload. As shown in the left figure, two-phase locking and OCC do not scale, because each Payment transaction updates its corresponding warehouse entry and each New-Order reads it, leading to one hot entry in each warehouse. Because the benchmark only have 4 warehouses, the 4 entries become a bottleneck. In contrast, 1Pipe scales linearly with number of processes.
The figure on the right shows the performance under packet loss. We can see that 1Pipe is more resilient to packet loss than traditional concurrency control mechanisms. This is because in the commit phase of 2PL and OCC, a locked object cannot be released until the transaction completes. So, the latency increases with packet loss rate because replicas wait for the last retransmitted packet to maintain sequential log ordering. In contrast, 1Pipe do not lock records. Lost packets only impact latency but have a low impact on throughput.

Now we look at limitations of 1Pipe.
First, 1Pipe cannot achieve atomicity of scattering under permanent failures.
Second, 1Pipe requires hosts to synchronize clocks at microsecond accuracy. Bad clocks will impact delivery latency but not violate correctness.
Third, a straggler host or network link will slow down the entire network.
Finally, 1Pipe assumes all participants are not adversarial, and we leave the security problems to future work.

Finally, the conclusion.
1Pipe proposes a causal and total order communication abstraction that delivers groups of messages in sender’s clock time order with restricted failure atomicity.
1Pipe achieves scalability and efficiency by utilizing programmable switches to aggregate ordering information while forwarding data packets as usual.
1Pipe can simplify and accelerate many applications including transactional key-value store, replication, independent transactions, and distributed data structures.
CATOCS is a controversial topic since 1980s. 1Pipe puts new insight into it in the context of data center networks. We expect future work to explore the boundary between network transport and applications.

Thank you for listening!