网络的智能应该放在哪里:网卡、交换机还是 xPU
达坦科技 DatenLord 前沿技术分享 NO.34
时间:2023 年 9 月 17 日上午 10:30
随着数据中心网络性能的提高,把网络相关任务卸载到智能网卡和智能交换机成为趋势。与此同时,GPU、NPU、存储设备之间的高速直连网络也成为趋势,这里似乎又没有智能网卡的位置了。网络的智能到底该放在哪里呢?
- Slides PPTX (32 MB)
- Slides PDF (15 MB)

以下是演讲内容的图文实录,主要由 AI 整理,我做了一些人工修正。

感谢各位在周末还来参加这个前沿技术分享活动。首先,我要感谢王总的邀请,让我有机会来到达坦科技做这个报告。今天给大家分享一些我关于网络智能的思考,包括智能网卡、智能交换机以及高速互联网络等等。
首先,我会简单介绍一些关于智能网卡以及智能网络设备,包括可编程交换机,以及它们目前的架构和使用方式。接下来,我会讲一讲我们的 Fast Interconnect,也就是高速的网络互联,包括像 NVLink 和 CXL 这些内容,以及我们未来的一些发展方向。

首先,我们来简单介绍一些智能网络设备,智能网络设备实际上包括有两类,第一类就是智能网卡,第二类就是可编程交换机。
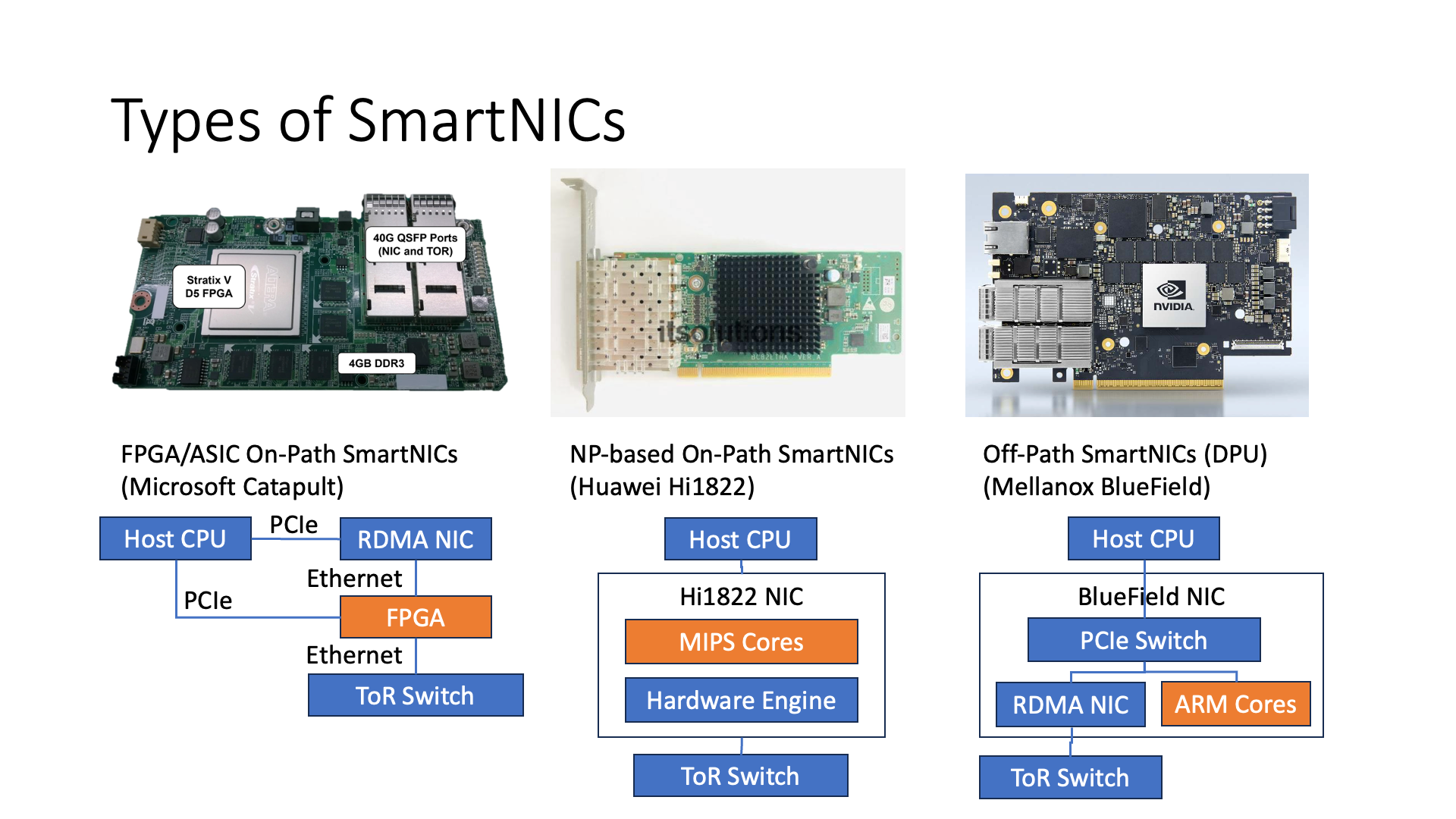
在智能网卡的种类里,大概可以分为三类,第一类是基于 FPGA 或者 ASIC 的 On-path SmartNIC,第二类是基于 Network Processor(网络处理器)的 On-path SmartNIC,第三类是 Off-path SmartNIC。那么,什么叫 On-path 和 Off-path 呢?
实际上,我们可以从这个图上看到,最左边的 FPGA 实际上是在网络的必经之路上面,也就是说每一个网络报文都要经过智能网卡的智能处理部分,所以这个叫 On-path。
比如华为的 1822 网卡,它也是一种 NP(Network Processor)。它也是说在它每一个报文处理的时候,都要经过这些可编程的核去处理。
但是比如说像 Mellanox BlueField 的这种智能网卡,他是属于另外一种 Off-path 的 SmartNIC。什么叫 Off-path?就是说这些 CPU 核它是没有在网络处理的一个关键路径上面,意思也就是说我如果想去发一些报文的话,比如说我如果是 CPU 直接去调用 DMA 的接口去发送,那么它直接是走的是左边这条路,它不会走到右边的 ARM 这边来。
但是如果说我要做 DMA,比如说想访问 Host CPU 上的一块内存,他就是要这么走过去走过来,或者如果要通过 RDMA 去访问外面的其他 Host,他也可以通过左边这条路去访问外面的 Host,也就是说它是属于相当于外挂式的这么一种方式。
接下来,我会分别介绍这几种智能网卡。

首先,第一个 FPGA 实际上最有名的就是微软的 Catapult,我之前也是在微软做了好几年 Catapult 相关的研究。
实际上现在国内也有很多公司,比如说像腾讯,也是在用 FPGA 来做 Bare Metal 机器,所谓 Bare Metal 就是说我这个机器可以整个作为一个整体,然后直接卖给你,你上边什么系统随便装,但是说我一样能够去保证它的安全性,保证它的隔离性,为什么?
是因为有一块卡是在外边的,相当于 CPU 这一块的东西其实是客户可以自己掌管,但是说底下的 NIC 和 FPGA 这块东西,是由我们的 Infrastructure 去负责管理的。
微软实际上最早弄 FPGA 并不是用来去做网络虚拟化的,它最早是用来去做 Bing 搜索的加速的,因为 Bing 搜索里边有一个搜索结果排序的过程,排序的过程中,它其实主要用的是一些深度神经网络的东西,所以说就把一些神经网络的东西放到了 FPGA 上面去做一些加速,当时部署的规模也没有特别大,也就 1000 多块卡。

后来故事的规模就大了。微软 FPGA 的负责人就是 Doug Burger,他就说我要给整个数据中心的每个机器上都部署一块 FPGA。干什么用?是用来做 Network Virtualization,因为说我们知道网络虚拟化它需要消耗很多资源,所以说如果只是使用我们的 CPU 来做网络虚拟化的话,它每个 Host 上可能要 5 个物理 CPU 核。如果算笔账的话,可能大概就是说整个 Host 的整个生命周期里面就相当于是损失了 4500 块美金,当然这个是按最大的来算的,意思就是说我如果所有的 Host 上所有的 CPU 全部都卖出去了,然后他就会损失这么多。
那么如果说我加一块 FPGA 的智能网卡,它会带来多少开销呢?这个 FPGA 如果说是零售的话肯定是比较贵的,就是一个 FPGA 就超过 1000 美金。
但是这个 FPGA 首先它用的不是最高端的 FPGA,当时它是用的是永远是比最高端低一代的 FPGA,因为说做网络虚拟化并不需要那么高的算力,够用就行了。
第二是因为微软的规模特别大,比如说上百万块的 FPGA,从论文这段截图里可以看到,规模足够大的时候芯片的设计成本可以被平摊,因此同等工艺下芯片的价格基本上是跟芯片的面积成正比的。所以说一块 FPGA 的价格其实也就是 200 多美金,再加上我们那块 RDMA 网卡 200 多美金,然后再加上还有刚才说的 DRAM,还有电路板的成本,整体成本实际上在 1000 美元以下。

在这种情况下,大规模部署 FPGA 成为可能。微软利用 FPGA 构建了网络虚拟化处理管道,这个管道被称为 GFT(Generic Flow Table),可以理解为一个查找表,其中包含一些规则,根据这些规则对报文进行匹配和处理,相当于把流表集成到了 FPGA 中。
由于采用了流表的方式,我们不需要频繁地重烧 FPGA,只需要在规则变化时修改流表即可。
利用这种方法,我可以大幅缩短 VM 到 VM 的延迟,同时大幅提升吞吐量。这是微软在 2018 年发表的一篇经典论文。
然而,FPGA 还存在一些问题,例如编程难度较大,普通软件工程师可能无法编写。此外,由于其芯片面积较小,无法容纳复杂的逻辑,因此我们只能将数据面的内容放入其中,而控制面的内容还应该保留在 CPU 上处理。

我们做了一项研究工作,使 FPGA 编程变得更简单,可以使用 C 语言编程,无需使用 Verilog。我们开发了一个编译器,利用 HLS 工具,可以将 OpenCL 编译成 FPGA 逻辑。然而,因为 OpenCL 编译能力较弱,因此我们在其上开发了一套框架,使其能够将我们定义的一种网络处理语言翻译成更高效的 OpenCL 语言,然后再使用 HLS 工具生成 FPGA 逻辑。这也是我们之前发表的一篇论文。

我们总结了一下,什么情况下使用 FPGA 比较合适,就是一个 10-100-1000 的规则。
首先,workload 需要使用 10 年,意思是如果我这个 workload 可能今年用一年,然后后面就不用了,那么使用 FPGA 开发的成本实际上是很高的。而且 FPGA 开发也不是特别敏捷,FPGA 开发的周期长,好不容易开发完,可能需求又变了。
其次,100 行代码,意思是如果用高级语言编写,可能需要写 1 万行代码,这在 FPGA 上可能放不下,因为 FPGA 上的逻辑门大小实际上是有限的。这并不是说 Verilog 代码的行数,可能 100 行 C++ 代码翻译到 Verilog 中需要上万行代码。
最后,1000 台服务器,意思是如果我这个服务本来就用不了几台机器,比如说它就是一个很小的 workload,最多就 100 台,那么我真的就买 100 台 CPU 服务器就行了,也不用再去想办法用 FPGA 去加速了。如果服务器太少的话,开发 FPGA 也是不值得的。
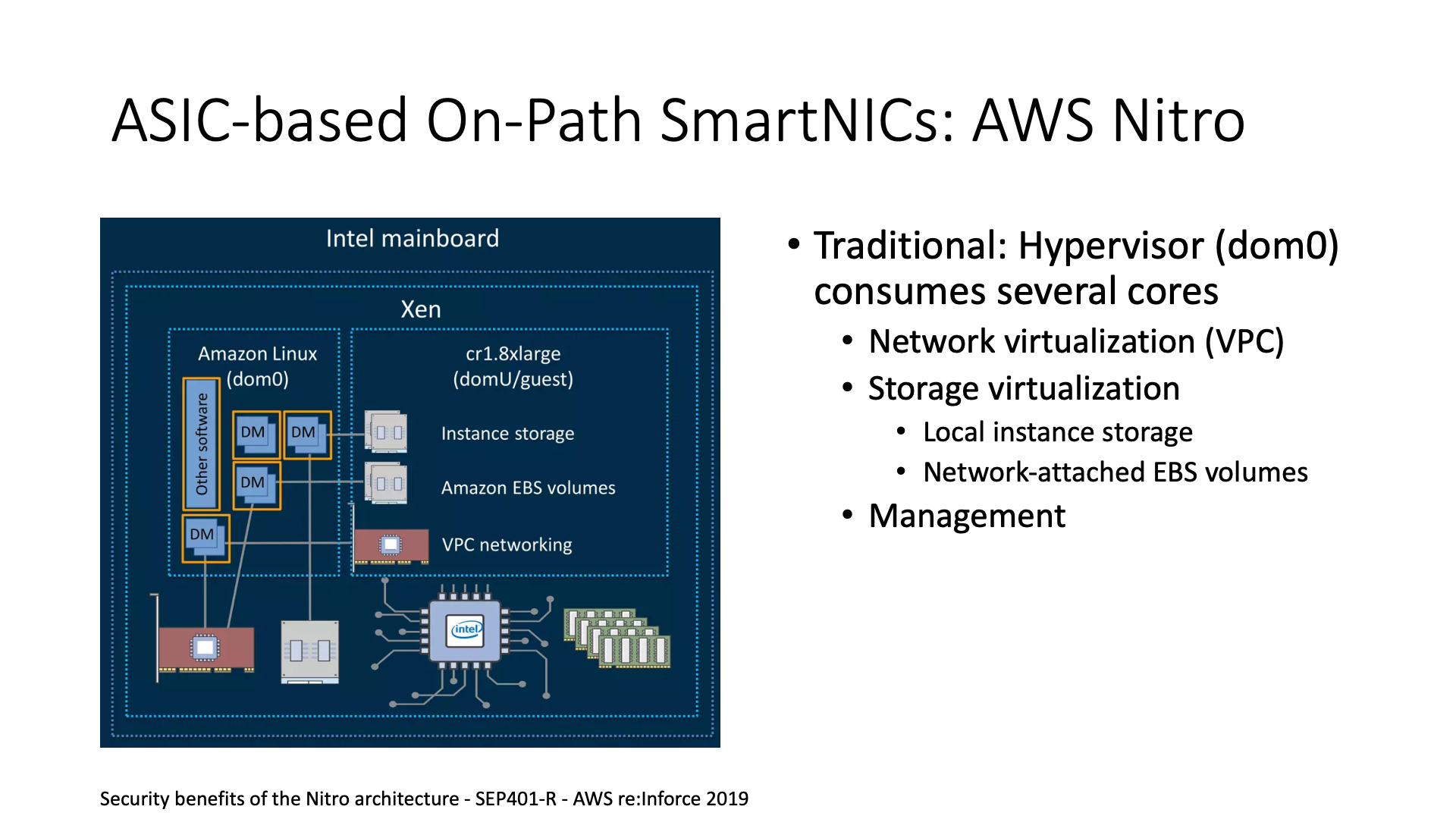
实际上,FPGA 开发和 ASIC 开发在某种程度上是类似的。例如,微软 Azure 最大的竞争对手 AWS,他们使用的是基于自研 ASIC 的 Nitro 卡。从架构上来说,他们基本上是一样的,只是选择了不同的技术路径,微软选择了 FPGA,而 AWS 选择了 ASIC,同样也是为了节约网络、存储虚拟化和管理的开销。
AWS 的做法是将原本在 CPU 上处理的内容,卸载到他们的智能网卡上。智能网卡实际上主要是一块基于 ASIC 的卡,可以理解为我们原来在 FPGA 上写的那些代码,也就是 Verilog,他们将其烧录成了 ASIC。
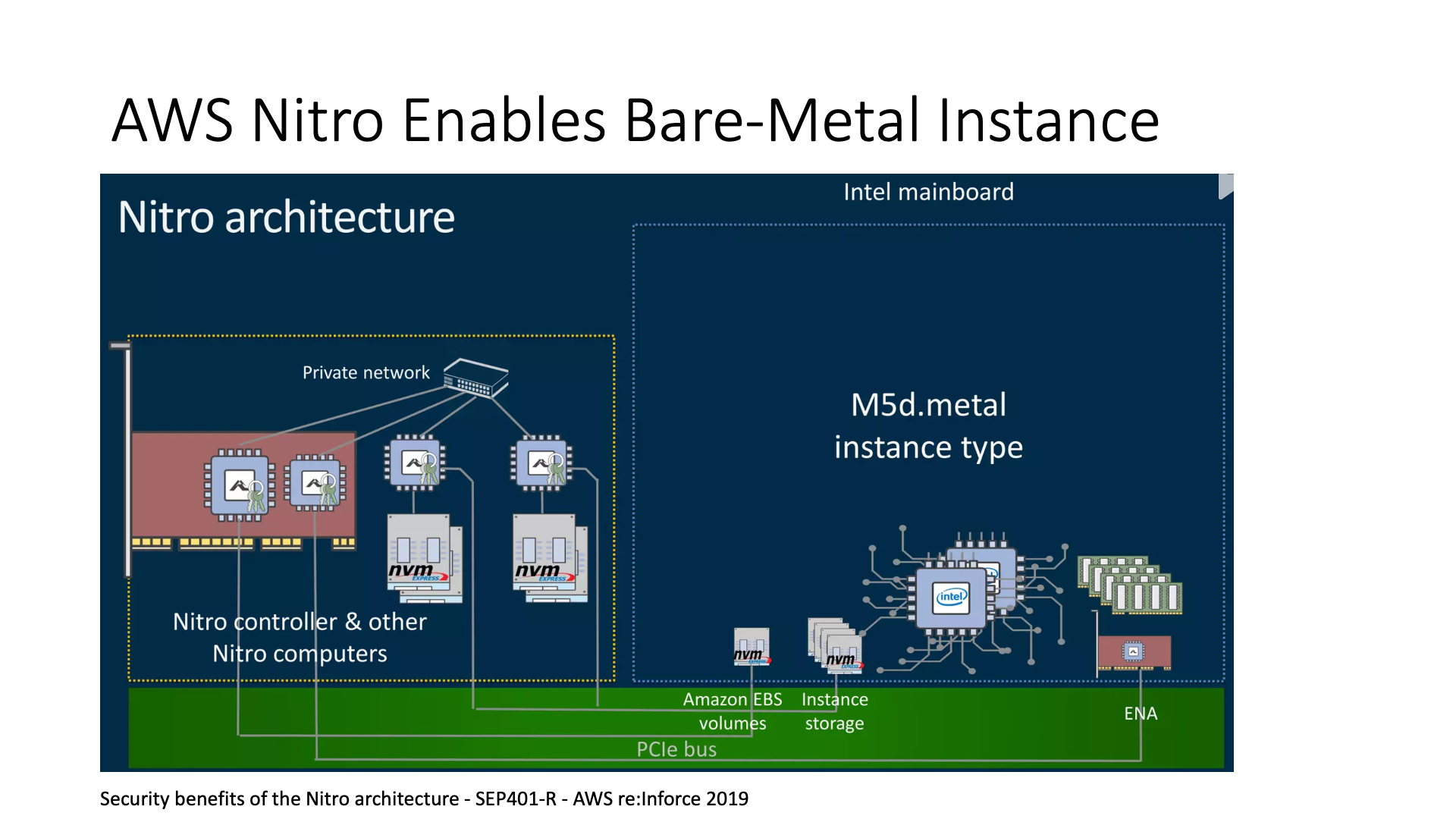
AWS 还开发了一个 Bare Metal Instance。腾讯的 Bare Metal 是使用基于 FPGA 的智能网卡去做的,微软、AWS 的 Bare Metal 也都是使用智能网卡这种方法,只是网卡内部的架构不同。如果没有这个卡,实际上 Bare Metal 是很难实现的,因为你需要额外添加一台机器来管理它。
例如,Bare Metal 机器肯定需要挂载云上的共享存储或网络磁盘等,我不能让它直接访问网络,这太危险了,所以一定要有一个人在外面看着它。如何管理这些东西,实际上就是智能网卡的工作。现在我只需要将这块智能网卡插入这台机器,然后这台机器就可以作为一个整体出售。
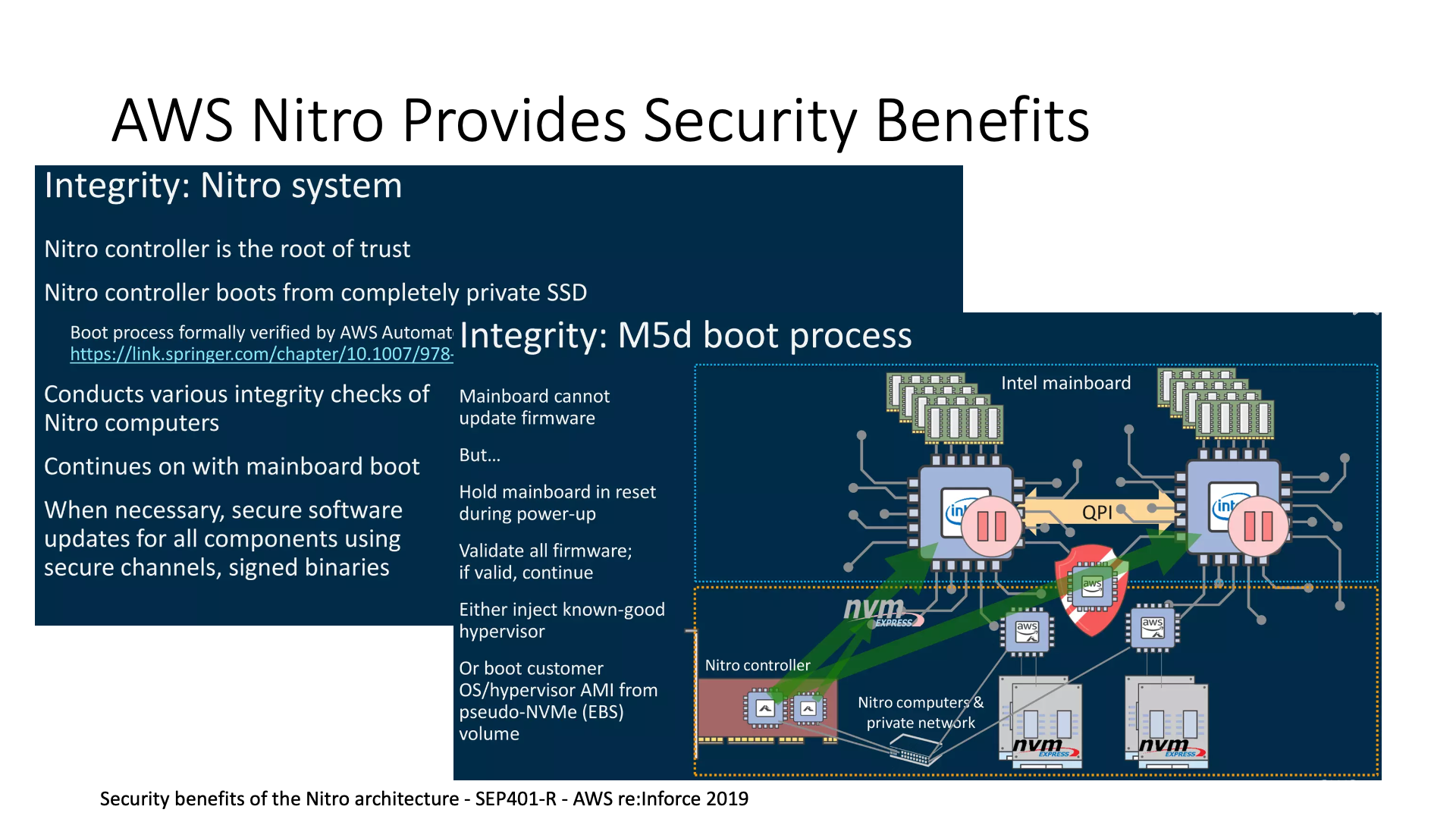
同时,像 Nitro,还有我们前面提到的 Catapult FPGA 都提供了一些安全方面的优势。我们可以将它作为一个可信根,意思是传统的可信根都是从 CPU 上来的,我在 CPU 上加装一个 boot loader,然后在 boot loader 上作为一个可信根来布局,但是这里有一个问题,如果磁盘的 raw 访问被攻破,然后 boot loader 被修改了怎么办?这个情况相当危险。
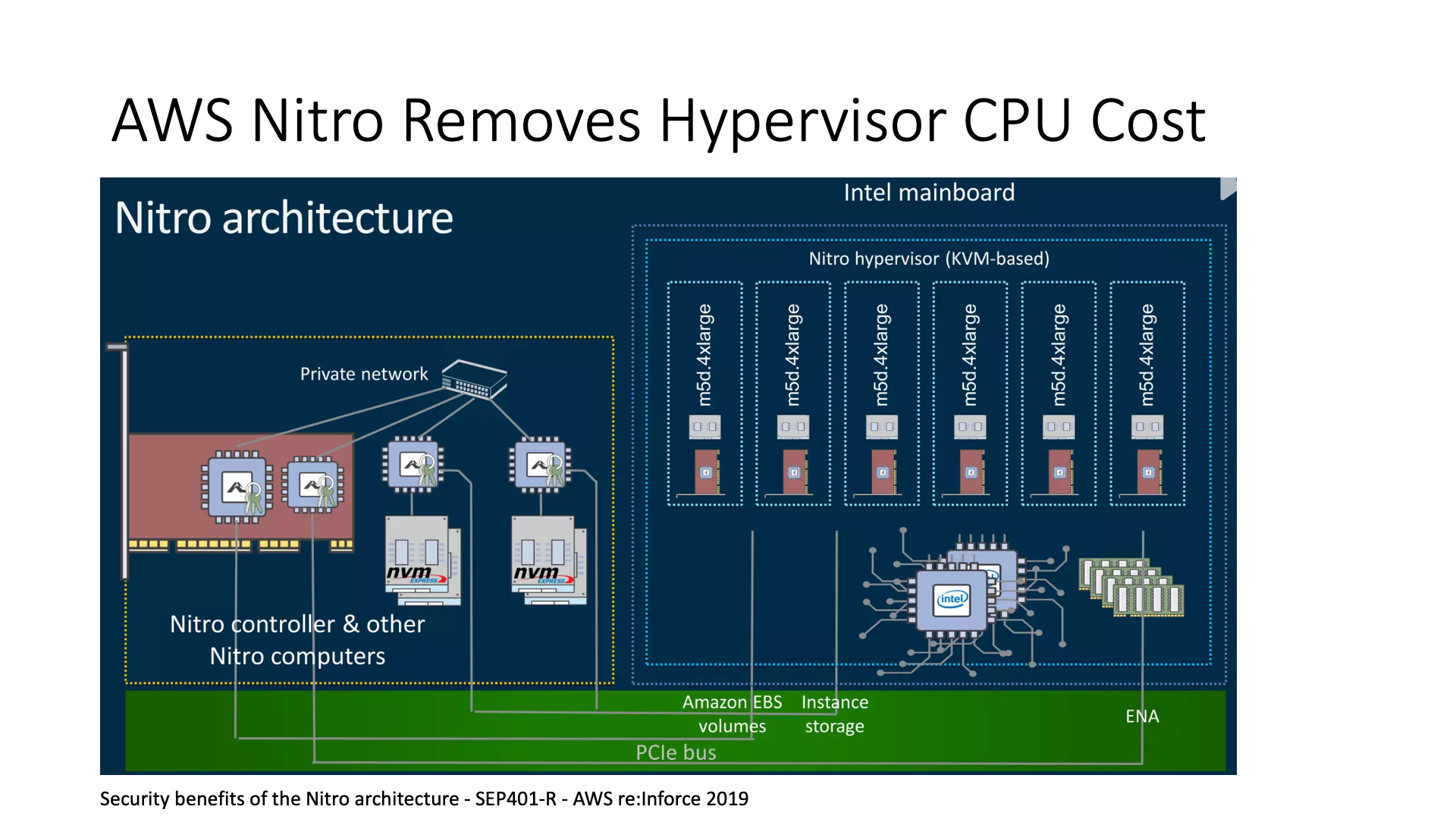
在 AWS Nitro 的架构中,它将 root of trust 放在了智能网卡控制器中,这样用户可以直接访问和管理整个磁盘,而不必担心会有其他问题。
Nitro 还提供了安全校验功能,在启动过程中,它也可以进行整个机器各种设备的 firmware 校验。

此外,Nitro 在安全方面还实现了一种被动通信(passive communication)。传统的通信模式可能是机器主动向外发起连接,可能攻击控制器,或者直接向 Internet 或者云内的其他主机发起连接,将敏感数据发送出去。
但是,智能网卡(SmartNIC)的存在改变了这一情况。因为这块卡在主机中,它与主机的 Hypervisor 建立了一个长连接,然后智能网卡再与外部的控制面(Control Plane)建立一个长连接。这样,它就不再需要主动发起连接,这种行为可以直接在网络层面,即交换机上,被禁止。这样就可以防止木马注入后,主动发起连接将信息发送出去的问题,这是一个加强的安全性的点。

当然,Nitro 还有一些其他的功能,比如它可以将原来在虚拟机(VM)中的功能,因为原来要运行 Hypervisor 的 Dom0 至少需要一个 CPU 核,然后将这个 CPU 核也移到智能网卡上,这样就可以有更高的安全性,同时也可以节约 CPU 核的开销。
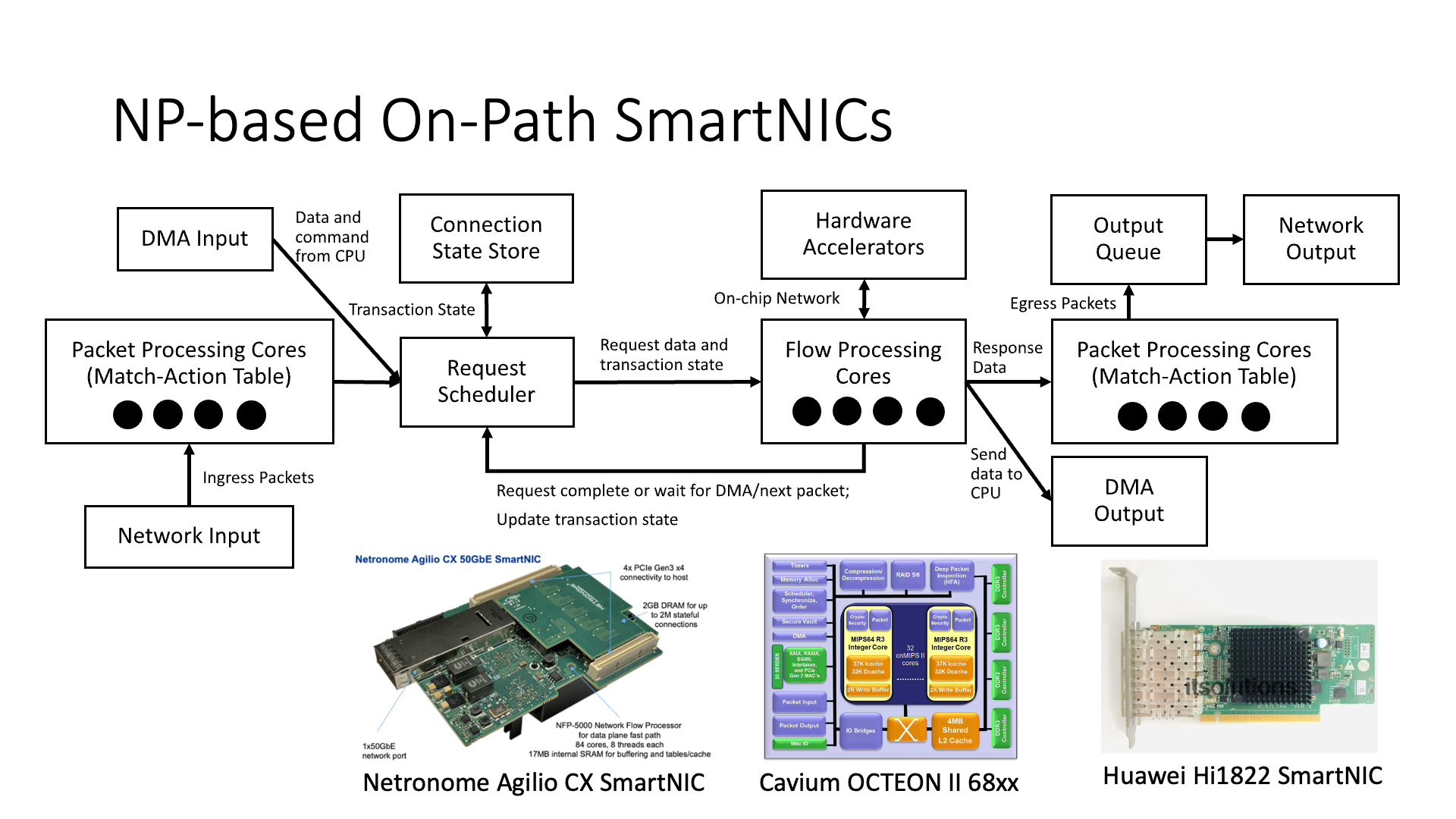
接下来,我们来介绍另外一类智能网卡。前面介绍的是基于 FPGA 或者 ASIC 的。我们现在介绍的是基于网络处理器(Network Processor)的这一类,它也是一个很典型的一类智能网卡。比如有 Netronome,还有 Cavium,还有华为的 1822 智能网卡,它们都是这种类似的架构,里面是一些小的 MIPS 核心,或者是 ARM 核心,用来处理数据。
图中的最左面和最右面两块写着报文处理核心的地方,实际上并不是通用的 CPU 核,而是一些匹配动作表(match action table),这个表有点像我们之前说的微软的 GFT(Generic Flow Table)的表。
图中中间的位置,还有一些流处理核心(flow processing core),这个是真正的 ARM 或者 MIPS 核心,它实际上是用来做一些逻辑处理的。比如在 RDMA 卡中,整个 RDMA(Remote Direct Memory Access)的引擎,大部分都是用 flow processing core 来实现的,它并不是把 RDMA 协议写死了的硬件。
这有什么好处呢?比如说我如果要更新它的拥塞控制算法,我就可以直接改这个流处理核心里面的代码,然后拥塞控制算法就改了。或者说是我想升级一下协议,与其他的卡,比如 Mellanox 的卡做兼容,我也可以改我的代码,这使得开发更加敏捷。这跟 FPGA 的道理是一样的。
网络处理器(NP)的编程看起来都是基于通用处理器核心的,但它并不是一个通用处理器,上面没有操作系统,所以 NP 上的代码并不是通用 CPU 上的软件,而是一般称为微码(microcode)。它并不比 FPGA 简单很多,实际上也是比较复杂的。
因为我们看到这个流处理核心并不是一个简单的外挂式的 CPU,而是与很多的硬件结构连在一起的。比如说它与硬件加速器(hardware accelerator)连在一起,如果我要在数据包上加一个报文头,我并不是在流处理核心里面写个 memcpy,把数据包后面的内容全都挪一下,然后再在头上面加一个东西,这样效率肯定很低。硬件加速器的功能是我直接把报文头插入到指定的位置上,然后剩下的内存移动的工作都是用硬件去做的,它的效率就会更高。
另外还有一个连接状态表(QP Context Table),存储每个连接的状态。如果我们在 CPU 上面写一个程序,它的状态怎么去存?肯定就是在全局变量里面弄个数组,或者是字典。但是你想,如果我在流处理核心上面搞个字典,然后这么多流处理核心都去并发访问字典,还要加锁,这个效率肯定就不是很高。
所以,NP 里面还是用硬件去实现的这个状态存储(state store),也就是说它的每一个连接的状态都是用硬件去保管的,然后我每次用 QP 编号去查找它,找到它了以后根据这个来调度,也就是这里面调度的事情也都是由硬件去做的,也就是说它是硬件调度而不是软件调度,这就是 NP 和通用 CPU 最根本的一个区别。
为什么我们需要在这里进行硬件调度?
我们知道,软件调度实际上存在很大的问题。因为我们知道,软件调度通常只能处理一个核,其调度能力是有限的。如果我们有多个核,我们只能进行负载均衡,也就是说,我们需要根据某种条件将输入的数据平均分配到多个核上,然后再进行处理。但是,这里存在一个问题,即如果有一个数据流特别大,比如有一个数据流可能是 80 Gbps,而另一个只有 20 Gbps,它们只能被分配到不同的核上,一个数据流只能在一个核上运行,这就导致了调度的不公平性。
然而,如果我们使用硬件调度器,无论是在 FPGA 上,还是在 NP 上,它都可以实现更公平的调度,因为它是一个硬件模块,所有的数据流都会经过它,然后再进行调度,这就是集中式调度和分布式调度的差别。
但是,仍然存在一些问题,如果一个数据流的流量特别大,仍然会有问题。因为如果一个数据流的流量很大,那么在处理完一个数据包和下一个数据包之间,它的状态需要不断变化。所以,如果上一个数据包处理不完,下一个数据包就不能处理。所以,这个时候,一个数据流通常只能在一个或几个核上进行 pipeline 处理。然后,在 pipeline 中,核的数量肯定是有限的,因为它是一个硬件的 pipeline,深度是固定的。
所以,NP 并不能将所有的核都调度起来,都去处理一个流上的数据包。这个时候,它的单流性能就会有一些局限。所以,这也是它与 FPGA 的主要区别,因为 FPGA 的流水线是可以编程的,复杂的逻辑可以在空间上展开而不是在时间上展开。

NP 的编程实际上并不像想象中那么简单,不是因为它里面有 CPU,就能随便编程。它的文档非常复杂,因为里面的各种加速器的接口都不一样。
NP 里面的代码还需要进行 pipeline 处理。比如说,我现在要访问一个数据结构,我是应该等它访问回来,还是我先切换到其他任务,然后等它访问结果回来我再切换回来?这就是 polling 和 context switch 的一个经典问题。因为 on-chip 的数据结构通常都很快,所以通常并不值得去做 context switch,通常都是等待完成,或者用硬件的 pipeline 来掩盖一下。当然,如果是 DMA(Direct Memory Access)的话就比较慢,就值得去切换一下。QP Context 的切换可能也是一个没有什么好办法的问题。
当然,还有一些其他的问题,比如 instruction cache 的问题,就是比如说我有 1 万行的 C 代码。1 万行的 C 代码,如果我全部做成一个基于 NP 的实现,它能被塞到卡的内存里面,但问题是它的高速缓存是放不下的,这样的话也会导致很大的性能问题。为什么说这个比 CPU 上麻烦了?是因为通用 CPU 的缓存都比较大,都是上兆的,但是 NP 里面流处理核都是小核,它的缓存都是几十 KB 这种量级。所以就得好好的去优化 NP 上的代码,需要把经常访问的热路径排布到缓存里面。这也是它的架构的限制带来的一些问题。
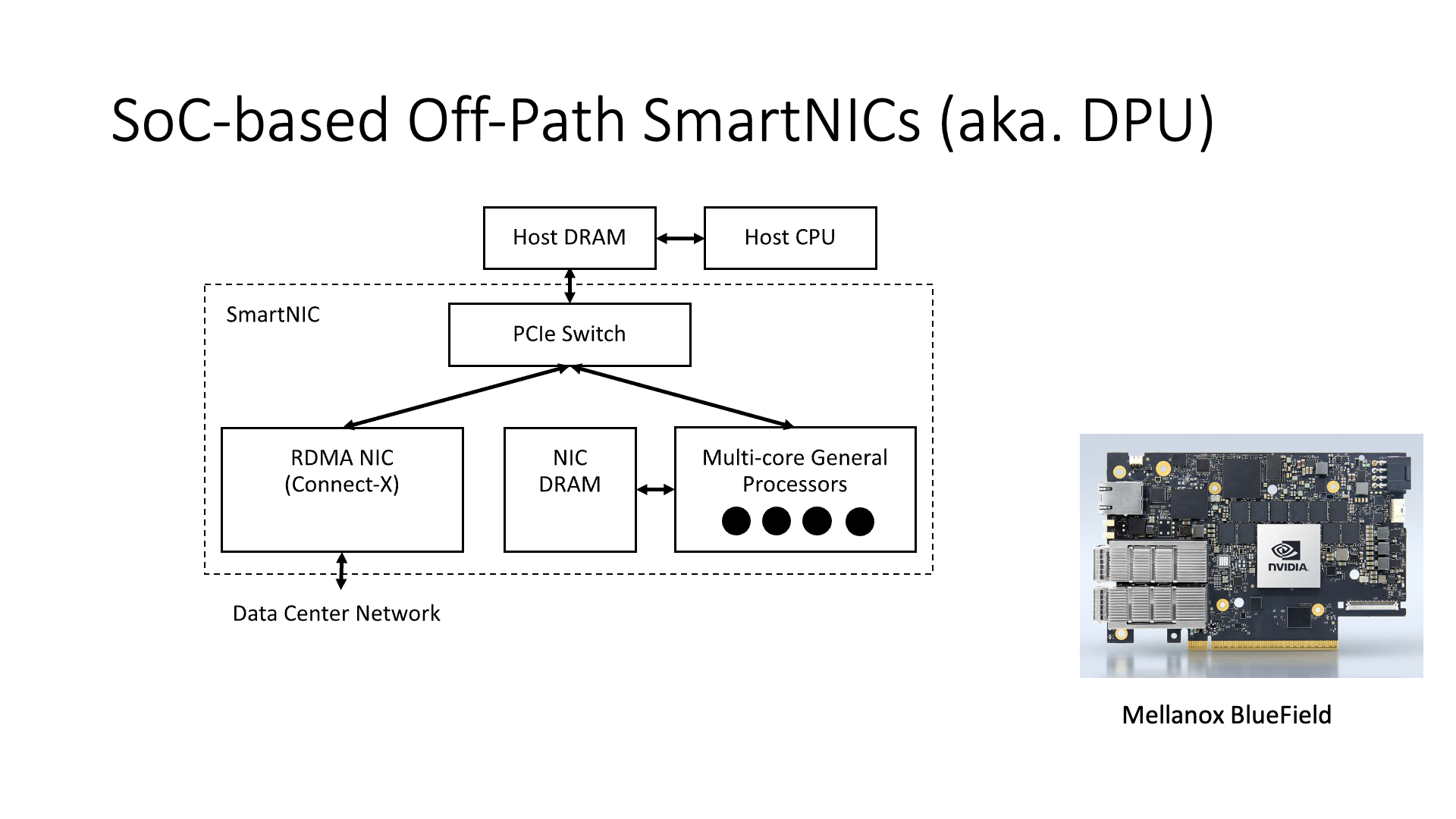
像 Mellanox,它走的是另外一条路,它就是说我搞了几个大核,我就不去做这个小核了。前面的 NP(Network Processor)架构,它里面的核通常都是小核,都是一些性能比较差的核。
但是,Mellanox 的 BlueField 的这块卡,比如说就搞 4~8 个比较大的 ARM 核。但是,这个智能网卡其实如果只是用这几个 ARM 核,它其实是有点鸡肋的,为什么呢?你看它这个架构,其实它是一个 off-path 的。前面几种架构都是 on-path 的,都是在网络报文的必经之路上去处理的。但在 Mellanox BlueField 里面,比如说在主机的 CPU 上面,去发一个 RDMA 请求,那根本和网卡里面的 ARM 核没关系,因为从左边的网卡部分直接走就到网络上面去了。
然后,如果这个 ARM 核想去访问 CPU 上的主机内存,好,它也得通过 PCIe switch 去访问。在老版本的 BlueField 里面,甚至它不能直接去访问 CPU,还需要去通过这个 NIC 绕一下才能访问,也就是一开始它没有做好这个 ARM 核直接去访问 Host 内存的这么一个通道,如果要访问的话,ARM 核先要通过 RDMA 访问到网卡,然后网卡再去访问主机内存,所以说整个的延迟都是 1.6 微秒往上走了。后来的 BlueField 2 里面把 ARM 核直接访问主机内存这条路给走通了,这个时候它通过 PCIe 访问主机内存就只需要几百纳秒的一个时间,这就快很多。

这就是 Mellanox BlueField 智能网卡(SmartNIC)的架构。它的架构与网络处理器(NP)的主要区别在于,首先,智能网卡内是一个通用操作系统,例如 Linux。然而,网络处理器内部并没有操作系统,也就是说,它需要编写微码(Microcode)。
其次,NP 在调度等方面,硬件的效率比外挂的 ARM 核高。NP 里面的流处理核虽然性能比较差,一个只有 1M pps 左右的性能,但 64 个核一起就有 64M pps。而 ARM 核虽然每个核能处理 3M pps,但是 8 个核加起来也只有 24M pps。所以 Off-path SmartNIC 里面的 ARM 核不能用来做大规模的任务。如果每一个数据包都从它那过一遍,那就受不了了。另外,ARM 核的处理延迟也相对较长,是 5 微秒和 2 微秒的区别。

所以我们看到,如果智能网卡上面运行一个普通操作系统,只是作为外挂的一些 CPU 核来处理,那么其实是很鸡肋的。英伟达也意识到了这个问题,所以他们也提出了 DPU 的架构。DPU 不应该将其核心当作普通的 CPU 核心来使用,因为这样的话性能肯定不会好。
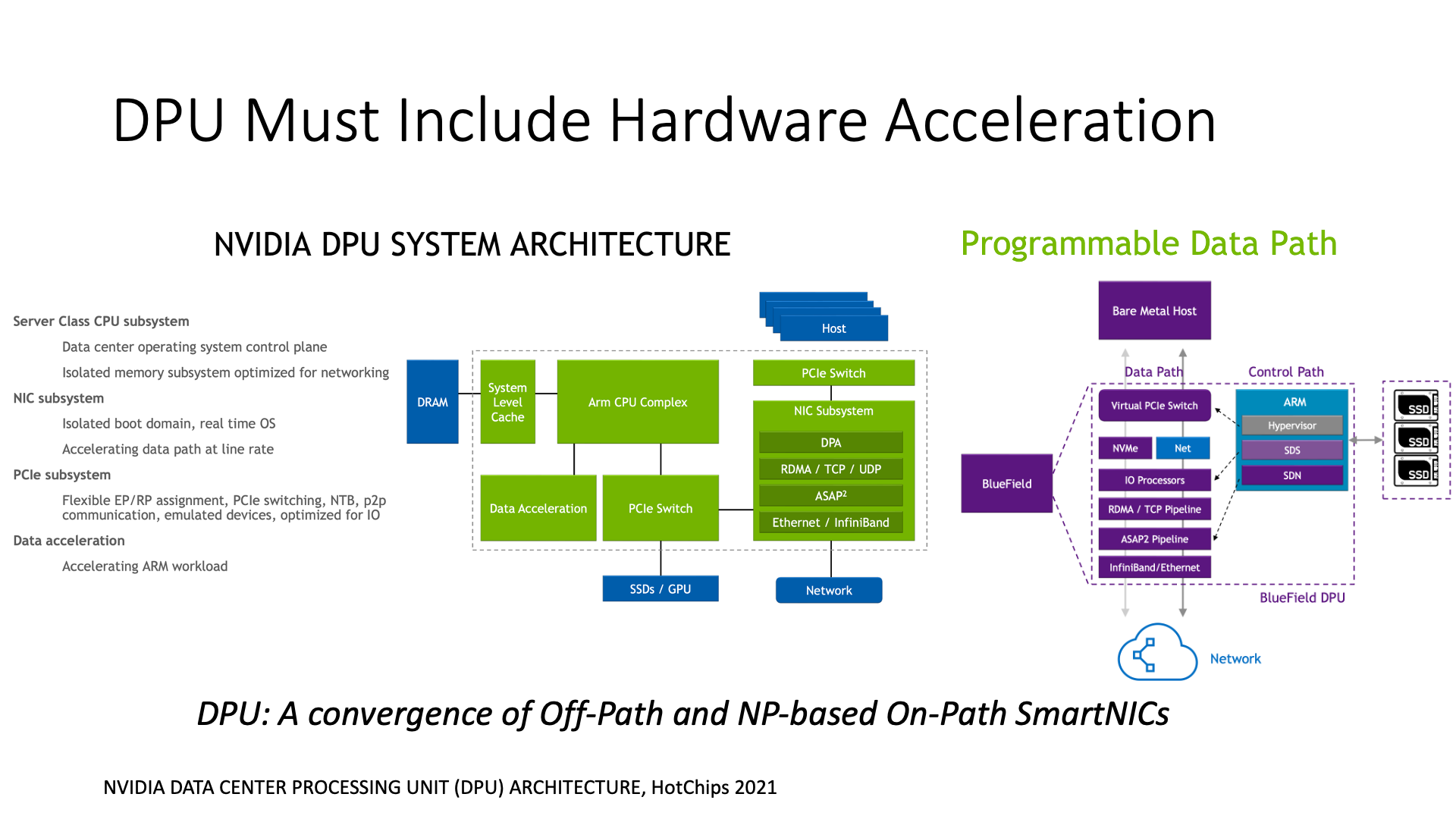
所以它也要增加一些扩展,相当于 DPU 又从网络处理器的架构里面吸收了一些东西。DPU 的架构实际上是 Off-Path SmartNIC 架构和网络处理器架构的一个结合。
首先,它并没有完全放弃在智能网卡上运行操作系统的概念,因为这对可编程性是非常有帮助的。如果上面可以运行一个标准的 Linux,然后上面又能运行一个 DPDK,即使是定制版本的 DPDK,对于用户来说,这些在 Linux 上习惯编程的人来说,他们是很习惯的。但是,如果是网络处理器,除非你去阅读那个上千页的文档,否则基本上就无法开始编程。所以可编程性是不一样的。
为了提升性能,DPU 增加了很多引擎,包括 ARM 核,然后这些 ARM 核里面它又增加了一块硬件加速器,这个实际上就像网络处理器一样,是把硬件加速的报文处理、加密、压缩等功能都放在这个地方。然后 DPU 还增加了一些查找表等功能,也放在了这里。
BlueField 还增加了一个可以直接连接存储的功能,可以直接挂载一些 NVMe 的磁盘,直接把磁盘挂到 BlueField 网卡上。这样做的原因是为了方便做存储虚拟化。之前说的像 Netronome 卡或是微软的 FPGA 卡,它们都用来做存储虚拟化的,NVIDIA 现在也把存储虚拟化的功能也放到 DPU 上来做。

那么如何选择这些智能网卡呢?
实际上,它们之间的主要区别就是,ASIC 和 FPGA 类似,NP 和 DPU 类似。一般来说,如果部署规模特别大的话,可能是 ASIC 和 FPGA 会更合适一些。
但是如果是 NP 和 DPU 的话,这个就适合小规模的,因为这样的话它的开发成本要比 ASIC 低很多。
这里还有一个问题就是硬件加速和它的可编程性之间也存在一个权衡。

接下来我们来简单讲一下可编程交换机(Programmable Switch)。交换机是除智能网卡以外的另外一类可编程网络设备。

目前可编程交换机最火的编程抽象就是 P4。现在可能差不多有 1/3 的 SIGCOMM 论文都会跟 P4 有一定的关系。
前面我们讲了可编程网卡里面经常会有查找表(match action table),不管是微软 FPGA 里面的 GFT,还是 NP 里面的查找表,还是 DPU 里面的硬件加速查找表。P4 可编程交换机里面最基本的抽象也是查找表。查找表匹配报文头上的一些字段,然后执行指定的操作。
其实传统交换机里面也是查找表,P4 有什么区别呢?P4 交换机的查找表里面的功能更丰富,例如可以做简单的计算,可以存储状态;此外,P4 的查找表深度比较深,一般有 16 级,而传统交换机里面的通用查找表一般不超过 3 级,这样 P4 交换机就可以用流水线的方式完成比较复杂的逻辑。
有了可编程交换机,我们能做什么事情,我们举几个例子。

首先,它可以做一个智能网卡和网络交换机协同的拥塞控制,这可能是可编程交换机最适合做的一件事,最靠谱的事。
比如说阿里的 HPCC(High Precision Congestion Control)是怎么做的?传统的拥塞控制,如果交换机上遇到了拥塞,就等到拥塞信号发到对端去,然后再返回回来,然后这个时候再去降速。但是这带来一个问题,就是降速可能并不是特别准确。所以它这个 HPCC 里面的 HP 就是 high precision,高精确度,也就是说交换机上面它能够有一个很高的精确度,然后去判断到底它拥塞的程度是什么样子,那就是用的可编程交换机的 INT(In-band Network Telemetry)的能力,然后它把拥塞程度反馈的更准确,这样它调整带宽的时候就调的更准确。
然后另外一个工作是华为的,这项工作是在 APNet 2021 年的会议上,谭博在他的演讲中提到的。他提出了一个叫做 Confined AQM(Active Queue Management)。我们的主要工作是实现了一个端网协同的拥塞控制机制,它是一个响应式和主动式的混合控制策略,这是它与传统拥塞控制方法的主要区别。在传统的网络流量控制策略中,包括 HPC(High Performance Computing)在内,通常是在网络出现拥塞后再进行降速处理。
然而,我们的目标是实现网络在未阻塞时就进行控制,以期网络永远不会阻塞。如何实现永不阻塞的目标呢?实现的方式就是在发送数据之前,先向交换机请求带宽分配。这意味着,它是一种基于分配的方法。也就是说,如果我想要发送数据,我不会立刻发送数据,而是先向交换机请求带宽分配。然后,交换机在分配了信用(Credit)之后,我再根据信用的允许量发送数据。这样,我就能保证在任何一个 RTT 内,发送的数据量都不会导致队列堆积。这样,我们就可以实现几乎零队列的接入,这是一种新的方法。
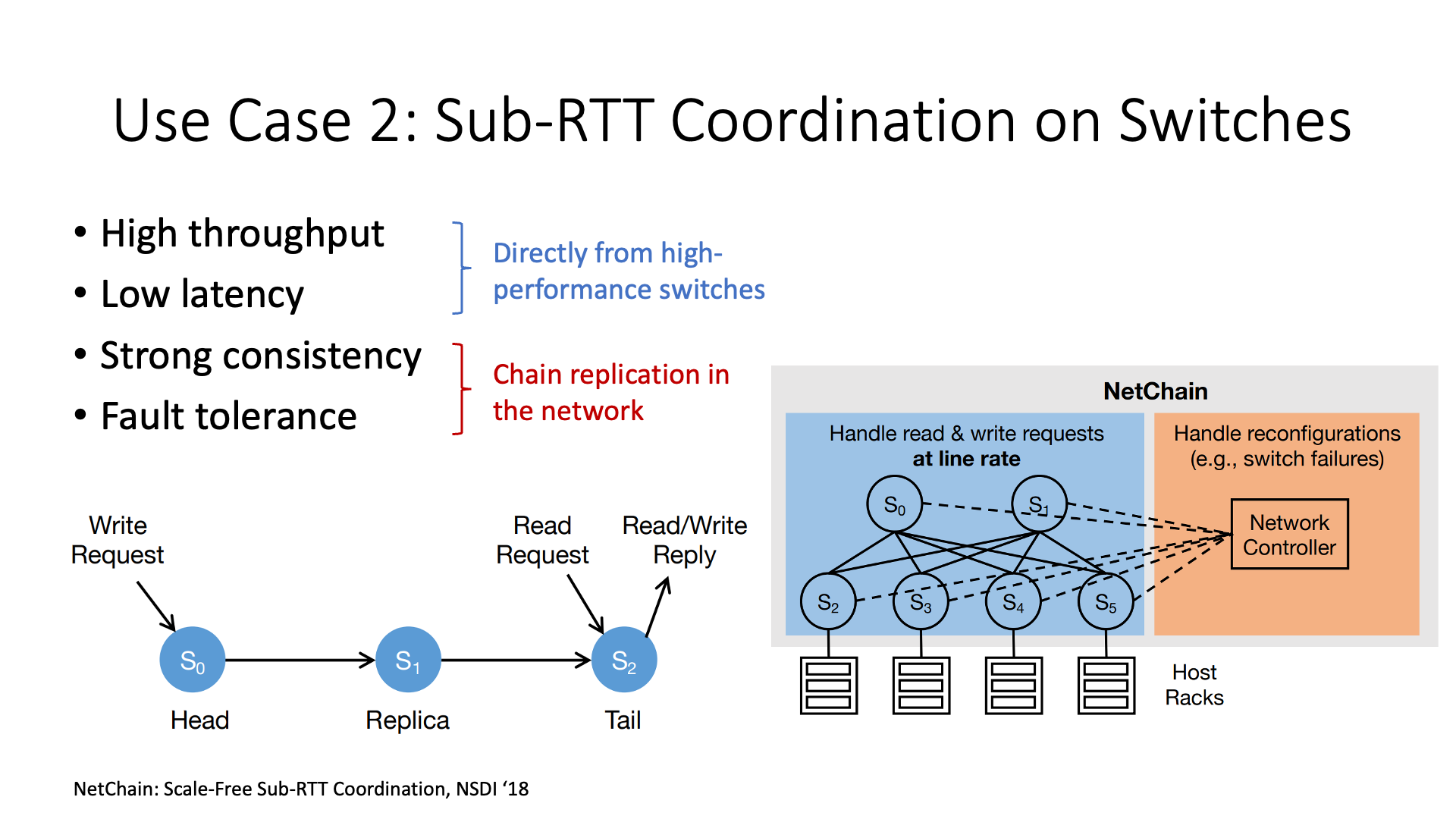
第二类可编程交换机的用途是加速分布式系统,这类研究的学术论文发表的最多。
分布式系统通常需要进行一些协调工作,比如发号器的工作。发号器就是给每个报文编号,然后分布式系统在进行一致性(Consistency)处理时需要用到这些编号。原来,交换机没有这个功能,需要发送到一个集中的主机,让它对所有报文进行编号,再发送到目标主机去,这个发号器主机就可能会成为一个瓶颈。现在,交换机具有这个功能,报文流过交换机的时候就自动打上了编号。这样,网络上所有的报文都自然而然地被编号了,我不需要到主机上再回来一趟,这样效率会更高。
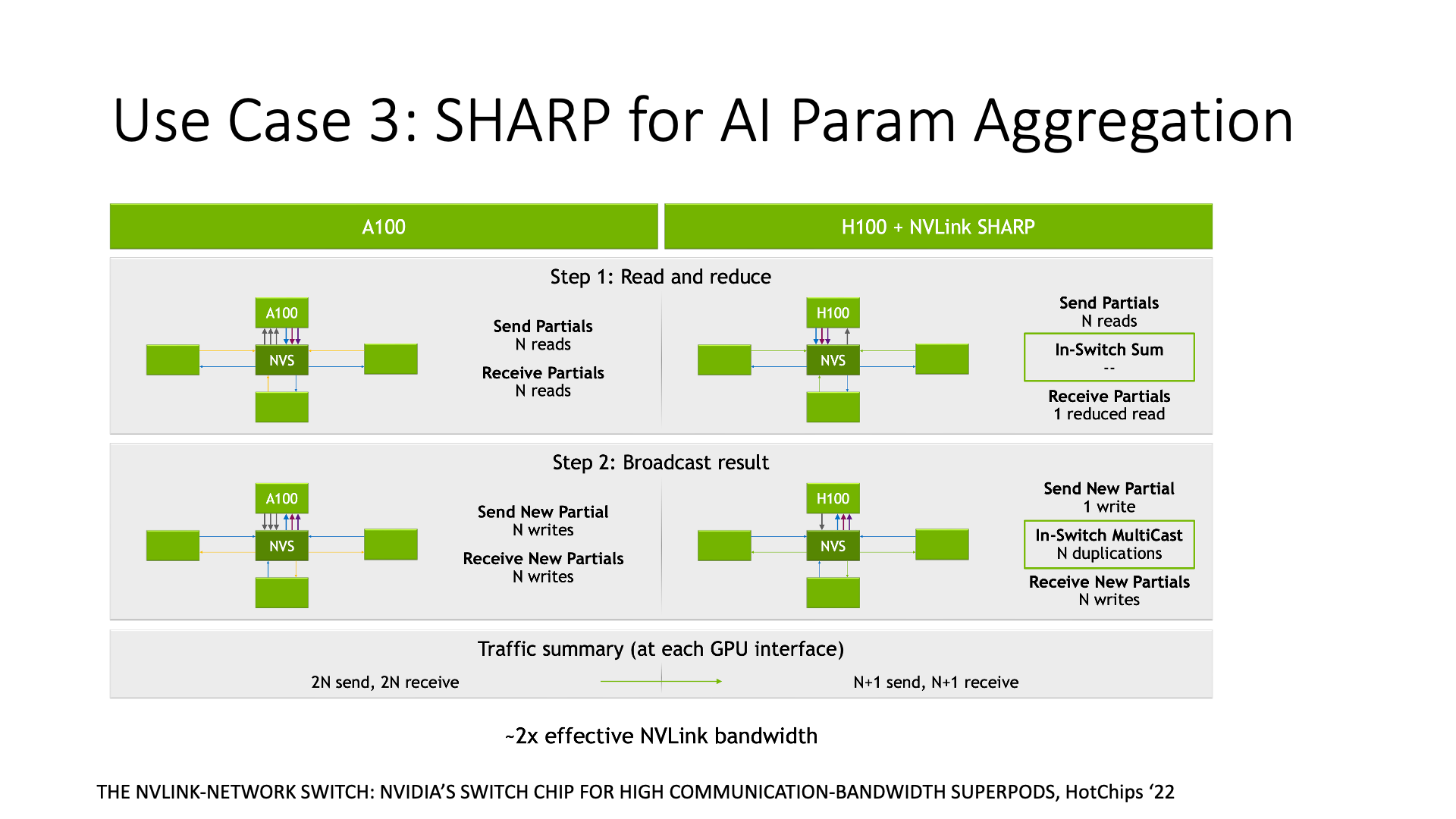
第三类研究是与 AI 相关的,比如英伟达的 SHARP,它是做数据聚合的。在 AI 训练中,通常需要进行一些数据聚合处理,比如计算各个节点梯度的平均值。如果使用传统的方法,我需要收集每个节点的梯度值,然后在主机上计算平均值。但是现在,交换机可以直接计算平均值,数据传输的次数从原来的 2n 次变成了 n 次,节约了一半的带宽。节约带宽有什么好处呢?在大规模训练中,带宽其实是比较紧缺的,当带宽成为瓶颈时,SHARP 就可以提升性能。

前面讲的 AI 相关的 SHARP 是英伟达交换机的功能。第一类拥塞控制所需的 INT 是很多交换机,包括 Broadcom 交换机芯片都有的功能。但是第二类工作,分布式系统的加速,需要的是 Barefoot 的 Tofino 交换机。但是遗憾的是,英特尔收购 Barefoot 之后,已经停产了这种交换机。
我们猜测,英特尔停产这种交换机的主要原因可能是他们想将主要精力放在 CPU 和 IPU 上,IPU 是一种类似 DPU 的东西。因为英特尔的主要产品是 CPU。如果交换机可以完成 CPU 的工作,那么 CPU 就可能卖不出去了。这是英特尔的战略选择,将所有的功能都放在主机上,而不是智能交换机。
包括英特尔控制的 PCIe,也是缓慢的挤牙膏,这也是商业上的选择,希望外设永远当个配角,核心的计算留在 CPU 上,CPU 永远当系统架构内的老大。
但是我认为其他的厂家,比如 Broadcom、华为和英伟达,他们的交换机都有很多智能功能,未来还会继续发展这个方向。
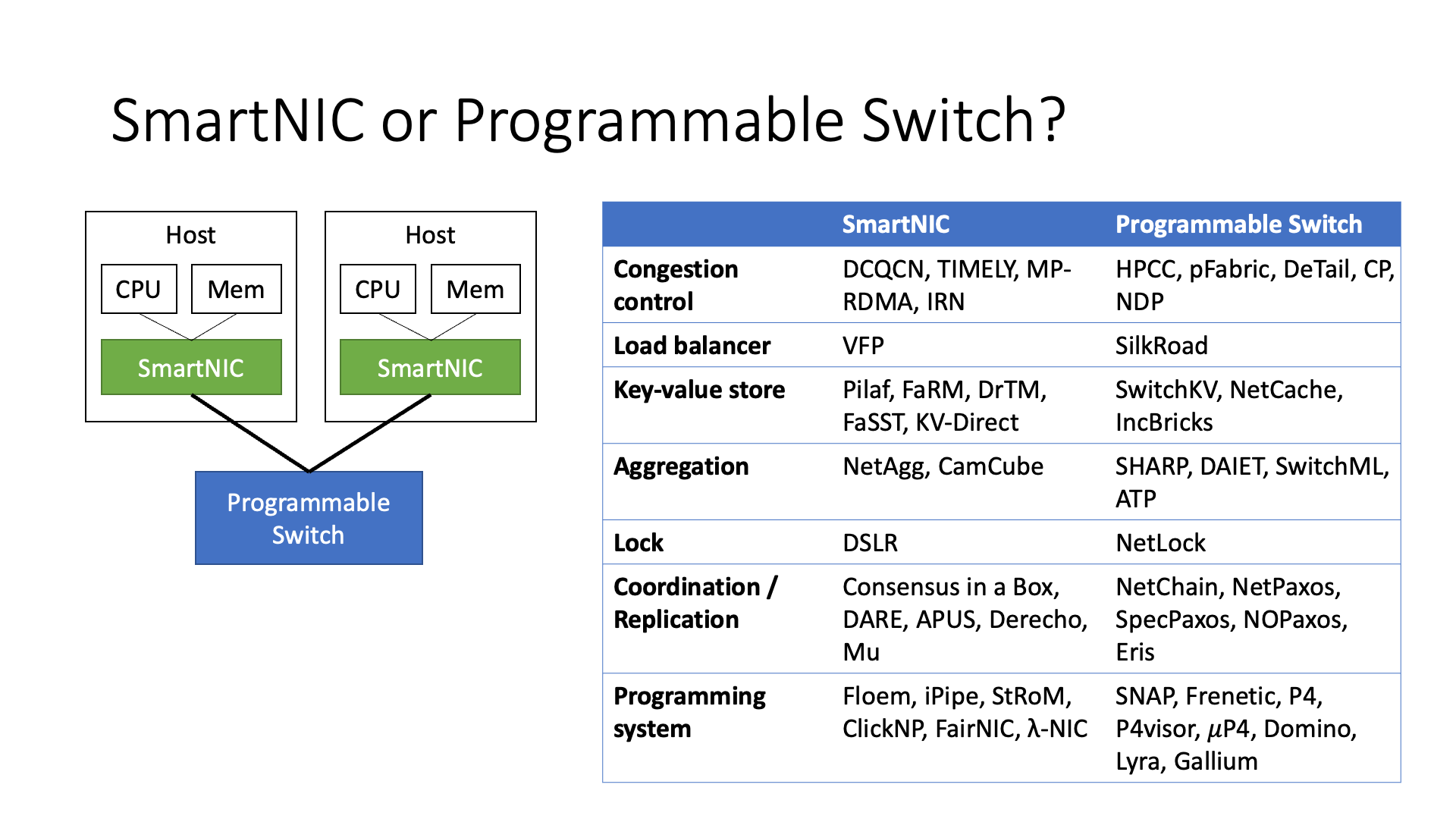
在交换机和智能网卡中,实际上有很多的研究工作,包括在学术界的一些工作。有些工作是在交换机上进行的,有些是在智能网卡上进行的,包括很多不同的研究,比如数据聚合、流量控制等。
但是这里有一个选择问题,因为智能网卡(SmartNIC)的视野比较窄,它只能看到自己的数据。但是它的计算能力比较强,因为它不需要处理大量的带宽,所以它只需要处理自己的数据,这样它的计算能力会更强。
另一方面,它可以更好地与一些协议结合,比如RDMA协议。而交换机可以看到更多的数据,所以像流量控制这样的功能必须在交换机上实现,否则它根本就不知道交换机上是否阻塞。
还有一些功能,比如数据聚合和协调器等,明显更适合在交换机上实现。所以在不同的场景中,每个设备都有更适合的功能。

前面我们看到,各种网络设备都变得越来越智能,包括交换机和网卡。另一条路是将智能功能全部放到端侧,而不是在交换机和网络中实现。
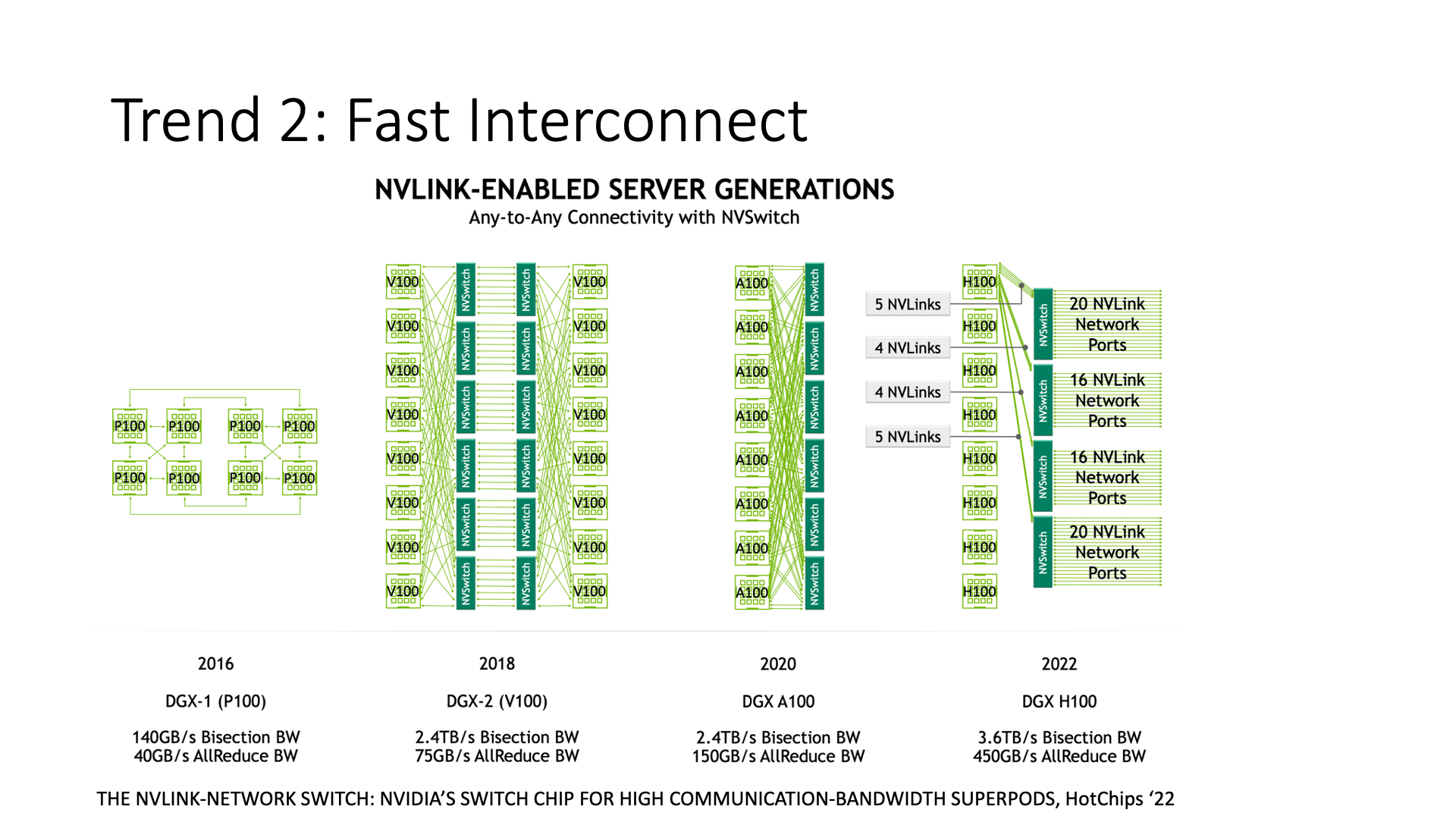
例如,大部分的英伟达网卡都采用了这种方式,因为我们看到英伟达的 GPU,它一开始的架构就是用 NVLink 让这些卡直接连接。为什么要直接连接而不使用 PCIe 呢?因为 PCIe 太慢了。PCIe 的发展就像是挤牙膏。为什么呢?英特尔一直想把所有的东西都放到 CPU 上去做,他不愿意把中间的带宽提高太多,因为中间带宽一旦提高太多,比如说 GPU 和存储设备之间都能够直接访问了,绕过 CPU,那么就没有人会购买高端 CPU 了,对吧?
所以,他是从商业的角度来考虑,他不愿意把 PCIe 带宽提高太多。英伟达看到这一点,他又发现 GPU 之间的带宽成为瓶颈了,又能做什么呢?
英伟达做了两件事情。首先,他先去做了一个 NVLink 的网络,我们可以看到 NVLink 的带宽是越来越高,甚至连 NVLink 交换机都做出来了,原来只是在一台机器内部进行通信,现在已经可以在一个集群内进行通信。
其次,它跟 ARM 合作,实现一个高性能的 CPU,比如说他们现在做了新的 Grace CPU,跟 GPU 之间也是直接高速互联。整个 Grace Hopper 架构里面就没有 PCIe 的事情,也没有 Intel 的事情。

那么,这里有一个问题,为什么 AI 就需要一个很高的带宽呢?
因为我需要做模型并行。在模型并行中,我可以把模型不同的部分分配给不同的卡,比如说我有 64 张卡,每张卡负责计算模型的一部分,然后它们之间再进行通信。最简单的一个想法可能就是既然模型有很多层,那我是不是直接把它分成很多层就够了?这就叫流水线并行。
第一是一个 GPU 可能都放不下一层的训练过程中所需的所有数据。第二个问题就是,即使一层能放下,如果分太多层,流水线太深的话,其实性能也会有所下降。因此,我们需要在模型并行中需要同时使用张量并行和流水线并行,在模型并行之外还有数据并行,这三种并行方式都需要一起使用。
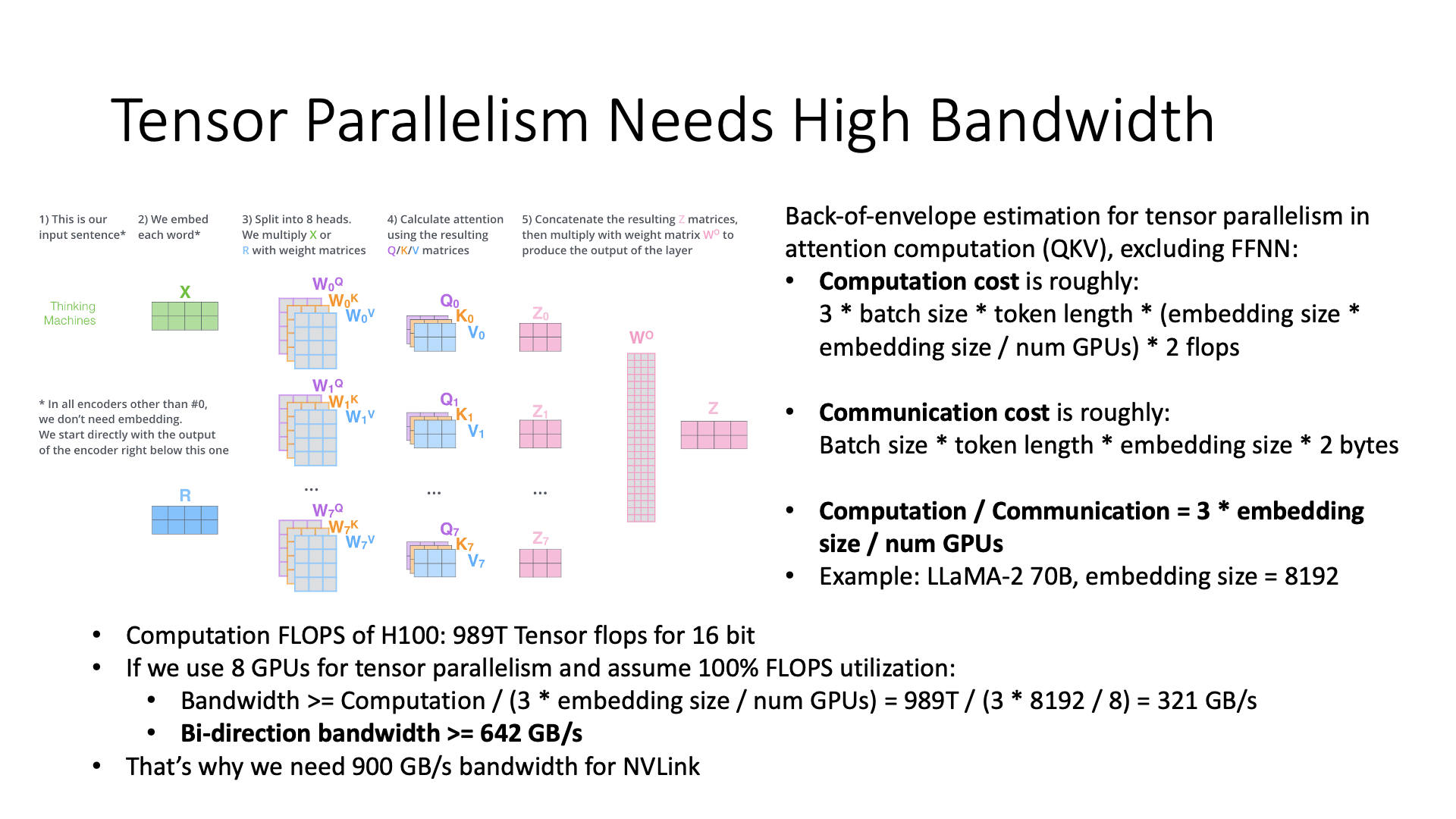
那么,为什么张量并行会需要很多带宽,我们可以做一个简单的估算。
例如,仅计算 attention QKV 部分的计算成本,忽略 FFNN 的部分。我们首先计算 computation cost,也就是计算所需的FLOPs,然后计算 communication cost。那么计算和通信量之比,就是 3 乘上 embedding size 除以做张量并行的 GPU 数量,对吧?
然后,如果我要训练一个 LLaMA 70B 的模型,代入计算后,结果大约是,如果我有 8 张显卡想要进行张量并行,我可能需要一个 642 GB/s 的带宽。
这样我们就知道了为什么在 NVLink 中我需要 900G 的带宽呢,128G 的 PCIe 带宽根本不够用。国内阉割版的 400G 带宽可能也是不够用的。
虽然这是一个粗略的计算,但大致就是这个数量级。

虽然张量并行对吞吐量的要求很高,但是延迟方面的要求并没有想象的那么高,因为 AI 训练过程中张量并行传输的都是一些比较大的张量。
延迟方面,我们简单算一下总的通信时间和计算的时间,把 latency 加进去,然后可以看到,如果进行张量并行,因为传输的数据较小,所以我们可以看到,一次只传输 16MB 的数据。有人说,16MB 的数据已经不小了,对吧?
但是你要除以它整个的带宽,就会发现这 16MB 数据 149 微秒就传完了。这个计算才需要 208 微秒。所以如果你想在同样的 900G 的网络上,充分利用计算能力,当然,充分利用计算能力是理想情况,假设能够充分利用,那么它的延迟需要在 59 微秒以下。
所以它需要设计一个 NVLink 这样的东西,实现 GPU 之间的直接通信。如果我从 CPU 上面去绕一圈,延迟就受不了,同时带宽也会打折扣,因为 CPU 的带宽肯定不如 NVLink 的带宽高。这就是 AI 训练的需求。
不过 59 微秒并不是一个很高的要求,比如 NVLink 的端到端时延还不到 1 微秒,RoCE RDMA 网络的时延也不到 10 微秒,只要不要在软件协议栈上消耗太多时延,都是可以接受的。但是需要小心的一点是尾时延(tail latency),比如网络拥塞了,或者发生 PFC Storm 了,那网络的时延可能一下子飙升到 1 毫秒甚至更高,这就没法忍受了。因此网络时延的可预测性是非常关键的。

所以,英伟达设计了一个叫做 Direct P2P 的 interconnect 架构,也就是 Grace Hopper 架构。在这种架构中,所有的 GPU 都是通过 NVLink 互联起来的。
然后,CPU 部分,通过 Bluefield 的 DPU,以及网络,把它互联起来,这就是它的整体结构。
上面的 CPU 部分实际上是用来进行大规模通信的,下面的 GPU 部分是用来进行小规模通信的。上面的 CPU 部分更多的是用来进行云相关的通信的。
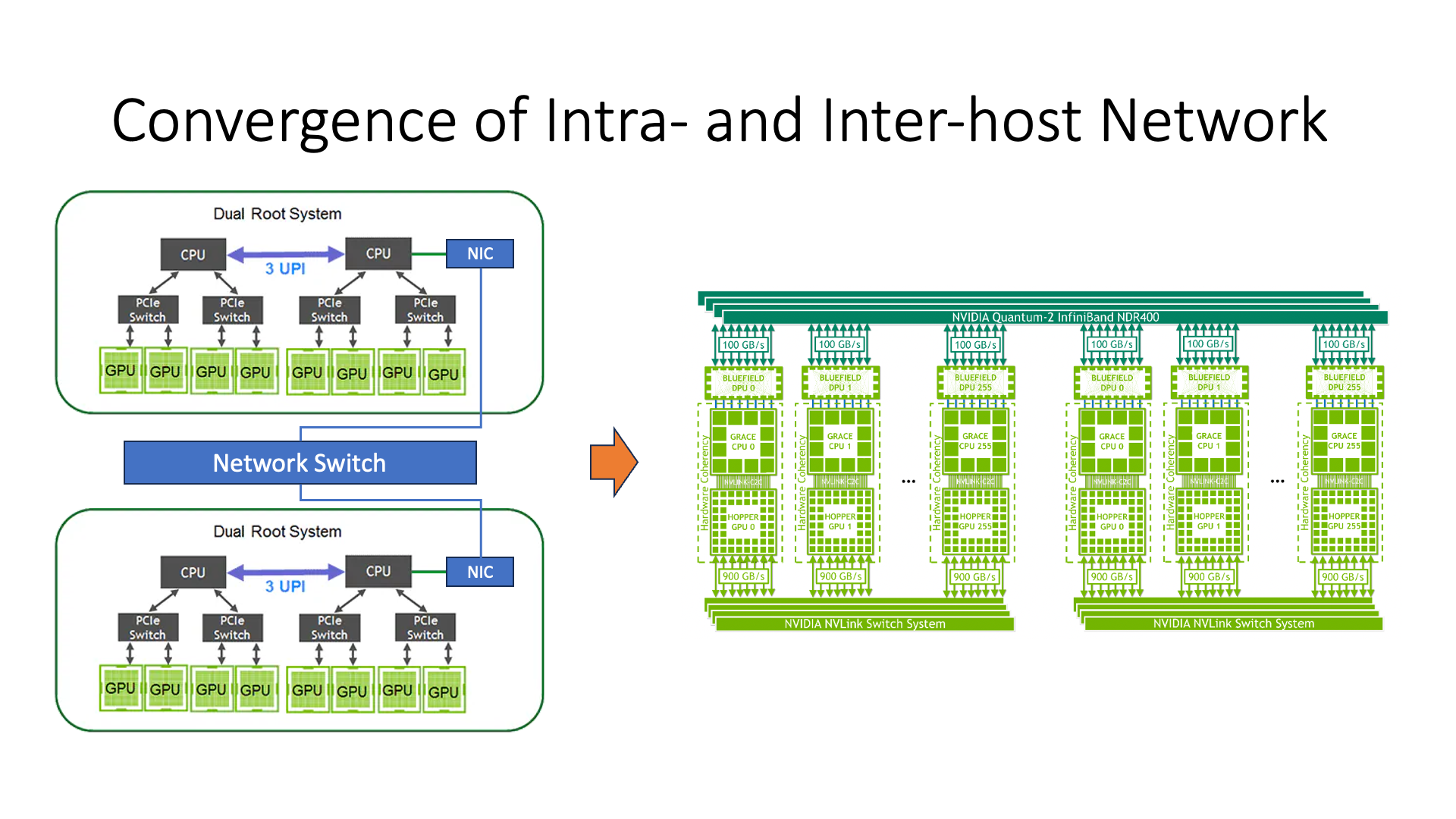
这个时候我们可以看到,老架构和新架构之间的一个主要区别,就是在老架构中,所有的 GPU 都是通过 PCIe 挂到 CPU 上面来,然后 CPU 再去连接网卡,再进行通信。所以这个时候我们可以看到,GPU 和 GPU 之间的通信性能实际上是较差的,对吧?延迟也高,同时带宽也较低。但是如果在新架构里,GPU 和 GPU 之间的通信效率就会高很多。
这里体现出一个点,就是主机内的总线和主机之间的网络,是融合在一起的。在这个图里,你就看不出来哪个机器,哪个地方是在主机内,哪个地方是在主机间了,对吧?之前的这个架构里我们一个框框一画一台机器是吧?然后原来的架构里很明显的区分了主机内和主机间的通信,主机之间通信效率就会比较低下,对吧?
这就是一个新的变化,包括华为在做的新型的交换网络,它实际上也是类似 NVLink 的一种结构,就是让主机内和主机之间的通信能够融合起来。
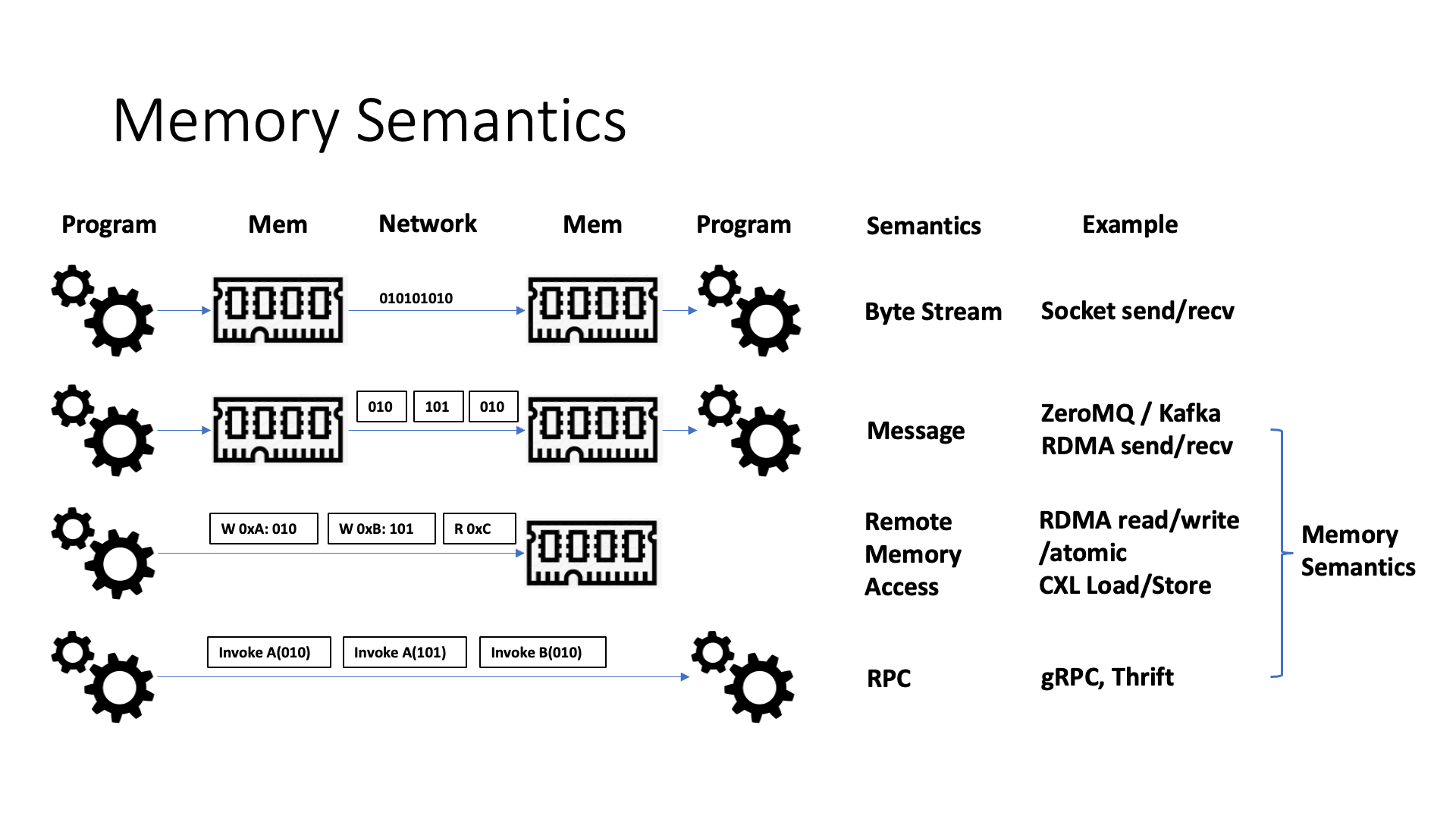
像 NVLink 这样的互联协议,通信的时候实际上是在采用内存语义来通信。内存语义是区别于原来的字节流的语义。字节流就是最简单的发送,比如 socket,但是 socket 效率是比较低的,为什么效率低?首先,socket 的字节流它是严格保序的,所以如果说我想一堆事情同时去发送,就没办法去充分利用并行性。
第二是因为它这个字节流里边没有一个 message 边界的语义,所以说它里边经常会需要有个拆包分包的东西。比如说上层的应用层协议,不管是 HTTP 协议也好,还是什么别的协议也好,它里面实际上都有一个应用层报文头的概念,应用层需要把报文从字节流里面提出来,这个时候它的效率就会比较低下。
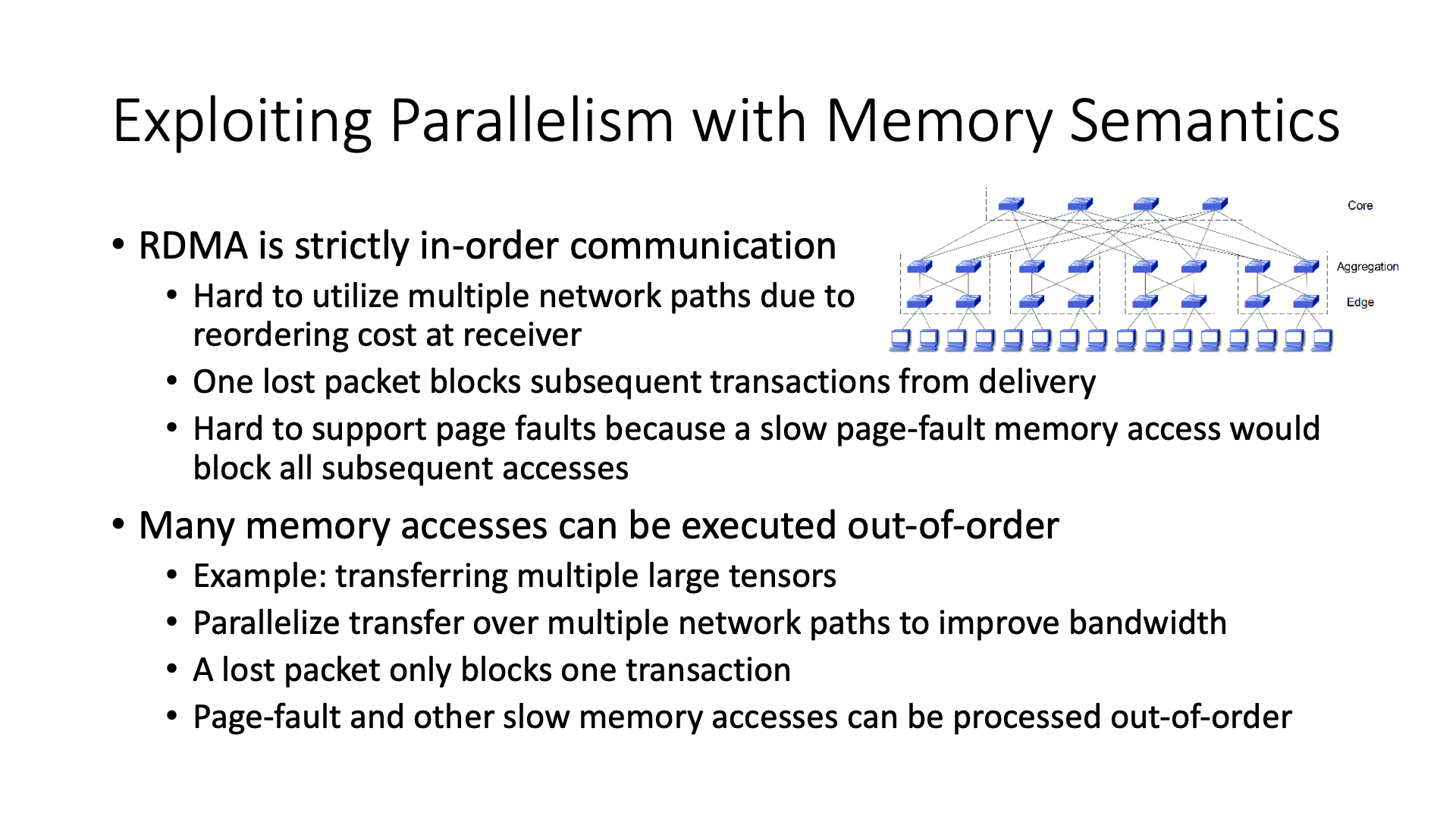
然后我们用内存语义了以后,它就解决了严格报序的问题。不管是 RDMA 还是传统的字节流,它一定是一个 in order 的严格保序的方式来通信的。
有了内存语义之后,我们知道内存访问不是严格保序的,它就可以把各个节点之间的多条路径充分的利用起来,因为在我们数据中心网络里多台机器之间,它们实际上是有很多条路可以走的。
然后另外还有什么好处,就是在故障恢复的时候效率也比较高,比如说如果说我这里边丢了一个包,然后你如果是顺序传输,后边的所有的 transaction(内存访问事务)都在后面等着,但是如果说是有一个乱序传输的模式的话,这个丢掉的包可以只堵住它自己的所在进行的 transaction,然后其他的这些 transaction 它就可以并发的去执行。
最后一点就是说现在 RDMA 它是不支持 page fault 的,也就是内存永远是一等公民,但是盘是个二等公民。所以说在 RDMA 的世界里面,它没办法去直接访问盘里的东西。为啥读盘里面的东西需要 page fault?因为需要在操作系统里边,把 page 里面的内容从盘里面捞出来,放到内存里,然后这时候 RDMA 才能访问。
RDMA 不支持 page fault 主要基于两个考虑。一是现在的网卡可能无法跟操作系统的内存管理很好的配合;二是在其 RDMA 的顺序传输中,page fault 是个繁重的过程。如果读取盘中的 4 KB 内容且没有任何缓存,那么至少需要几十微秒的时间,这样会阻塞后续请求,降低效率。
如果我们引入乱序传输机制,那么网卡上的 page fault 处理就可以得到改善,这就意味着地址实际上可以完全是虚拟的,部分在主机的内存中,部分在盘中。访问数据的远程应用不需要关心数据在主机内存还是盘中,如果它是在盘中,网卡可以将数据从盘中取出,查页表,查到以后就可以从盘中拿出来。这样,整体的访问效率可能就能大大提升,可以用网卡去帮忙处理 page fault 工作。
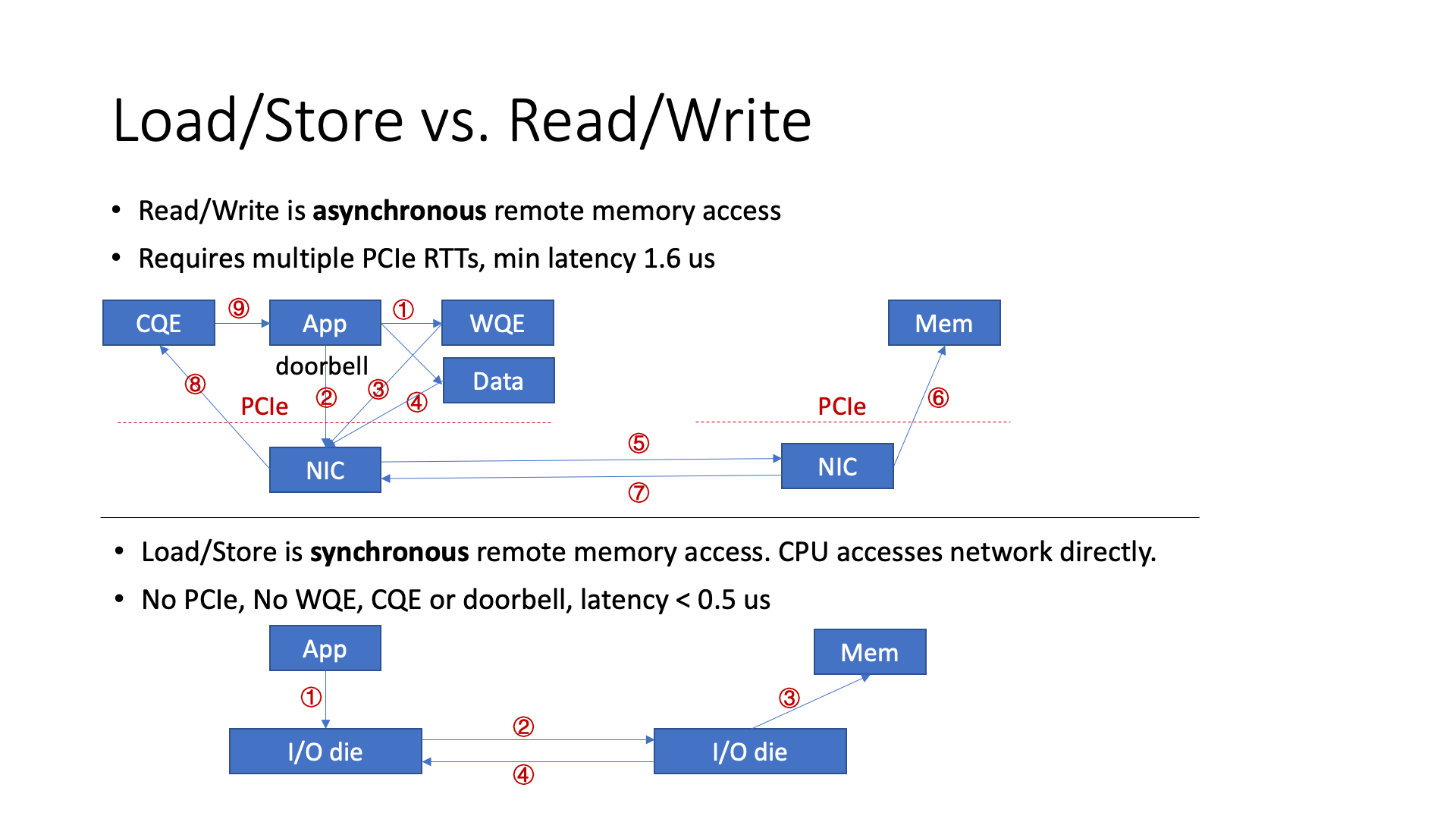
另一种可能的改进是使用 load store 来取代 read write。Read write 是传统 RDMA 中的一个操作,传输数据的过程实际上非常复杂,整个流程非常长。如果我们使用 load store 的话,那么它实际上是一个同步的方式,整个流程较短,所以延迟会比较短。
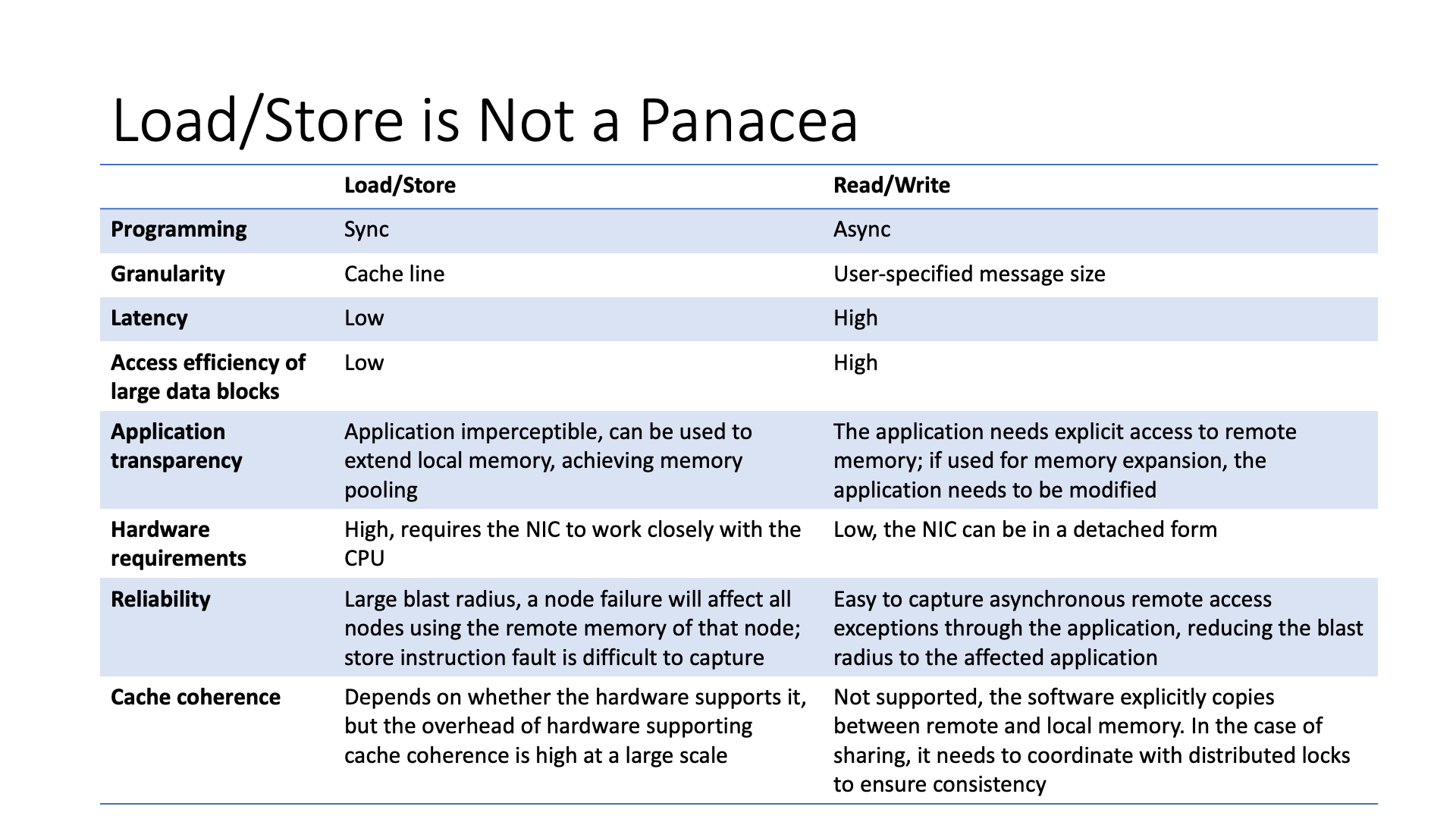
但是这并非适用于所有情况。虽然 load store 编程简单,但是如果是大块的数据,每个核都需要等待,它的流水线深度是有限的,效率可能会较低。
另外,load store 对于故障的支持也不足,如果有一个内存访问卡住了,可能 CPU 直接就崩溃。就算 load 请求可以比较容易的定位到是哪个进程,但异步的 store 指令产生的异常很难处理,CPU 自己都记不住是哪个进程导致的 store 异常了。但是如果采用 read write 的异步方式,故障处理就会容易很多。
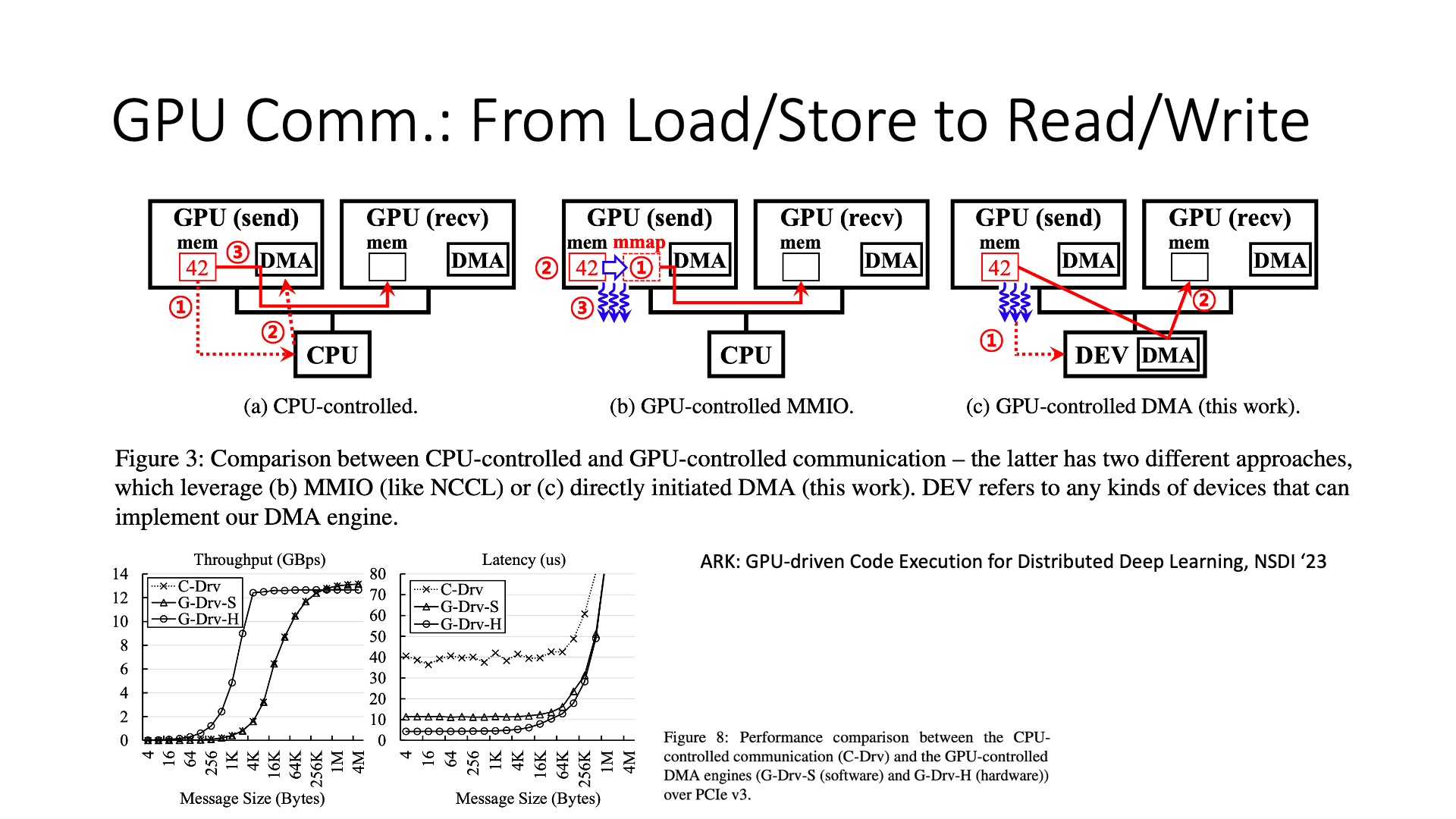
最近,微软也做了一个工作,他们将 load store 改成了 read write,使得 GPU 和 GPU 之间的通信比原来通过 load store 的效率更高。也就是说,在相同的硬件条件下,如果我采用 read write 的方式进行通信,当数据量大的时候,可能会比原来直接通过 CPU 或 GPU 的 load store 指令访问远端内存的方式效率更高,可以减少一些 CPU 和 GPU 核的浪费,还能减少缓存的浪费。
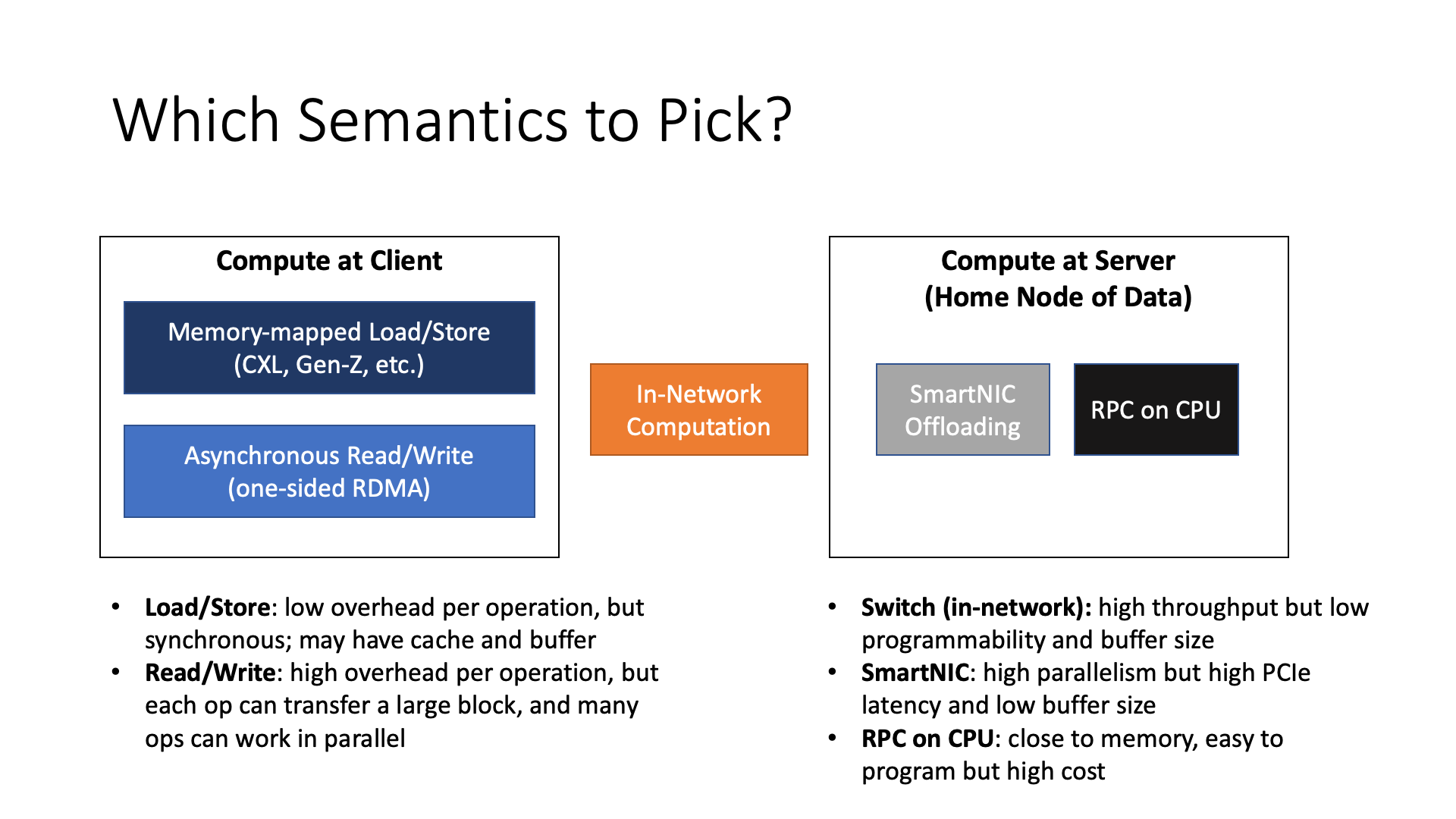
前面我们讨论了直接访问内存的语义,包括 load store 和 read write,它们各有不同的优缺点。更前面我们还讨论了网络中的多种智能设备,包括智能网卡和可编程交换机。
假设数据在远端,那么我们有几种不同的数据访问方式。最简单的是将所有计算都放在本地的 CPU 或者 GPU 上,也就是用内存语义来直接做远端内存访问,不依赖网络设备,那么有 load store read write 等不同的方式。
而如果将计算放在网络中,包括使用 SmartNIC offloading,还有 In-Network Computation 等不同的选择。当然,如果数据在远端,SmartNIC 也需要用 load store 或者 read write 的内存语义来访问远端的数据。如果用可编程交换机的话,因为可编程交换机目前还没有直接访问远端内存的能力,需要先发一个请求去把数据从远端抓回来,然后在数据回来的路上用可编程交换机来随路处理。
我还可以将计算放在远端的 CPU 上,比如我可以做一个 RPC 调用,也就是把计算任务发送到数据附近,这也是一种选择。
每一种选择都有不同的 trade-off,所以并不是一种 one size fit all 的解决方案。未来有一个很有趣的工作,就是是否有可能做一个自动化的系统,能够决定将计算放在哪里。

最后,我认为未来 AI 和 Cloud(云计算)一定是整合在一起的。
传统上 AI 集群和云计算集群是分离的。这意味着在 AI 集群和云计算集群之间传输的网络带宽(Bisection Bandwidth)较低。传统的 AI 处理和大数据处理是比较分离的流程,因此也不需要那么多网络带宽。但是未来 AI 一定是大数据处理过程中必不可少的组件,中间需要很多的数据交互,分离式集群的通信效率就比较低了。
此外,AI 集群里面的 GPU 之间一般都是直接通信,也没有虚拟化这一套东西,就算加上个智能网卡来做虚拟化,开销都太高。因此很多人认为 AI 网络和云网络不可能整合。但是为什么虚拟化一定要在 CPU 或者智能网卡上呢?为什么高速通信的硬件不能原生支持虚拟化呢?不能因为现在 NVLink 还不支持,就说这不可能吧。

在英伟达的模型中,AI 网络是下面的框框,Cloud 网络是上面的框框。也就是每个计算单元,可以认为是一个 GPU 加上一个 ARM CPU,在 CPU 一侧连了 Cloud 网络,在 GPU 一侧连了 AI 网络。CPU 和 GPU 之间也是通过高速网络互联。
你能说清楚这里面哪是主机内,哪是主机间吗?这就是主机内和主机间网络的融合,主机的概念在网络互联中被淡化了。每个计算单元需要执行与 Cloud 相关的操作时,它可以通过 DPU(Data Processing Unit)访问 Cloud 网络,DPU 可以解决我们之前提到的与虚拟化相关的问题。
GPU 之间直接互联的效率是最高的。因为它的通信带宽比上面的 Cloud 网络差了一个数量级,差了 10 倍。所以,我们可以在上面的 Cloud 网络里添加 DPU,但最好不要在下面的 AI 网络里添加 DPU,否则效率会很低。
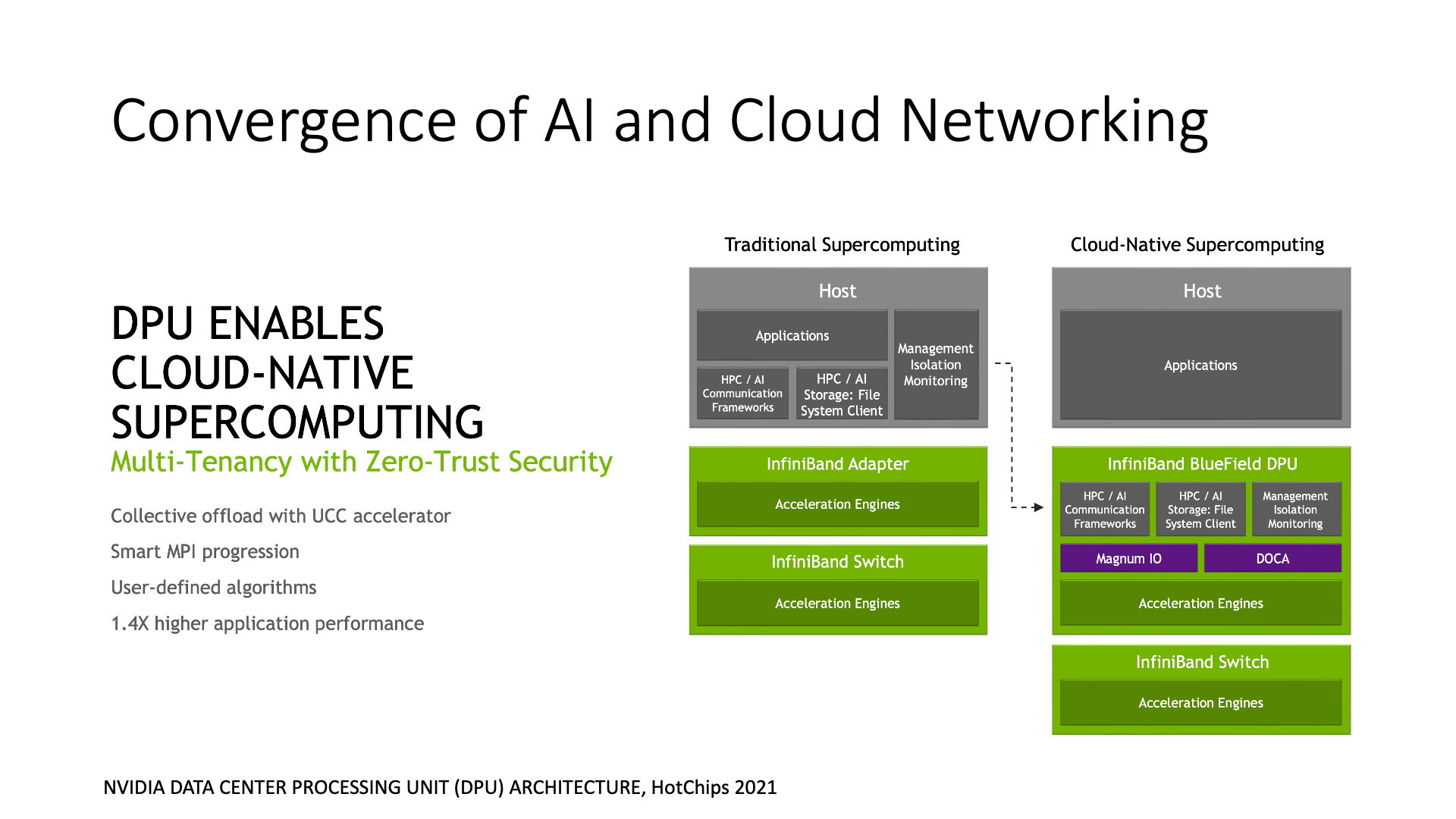
在 DPU 中,也可以做很多加速的工作,将主机上的一些网络功能放到 DPU 中。这张图里重点讲的是 AI 相关的集合通信加速。集合通信并不是简单的把数据传过来就行了,还有计算过程,也就是要把不同节点上传过来的数据做一个汇总(reduce)操作。不管是收发网络消息,还是计算 reduce 操作,都是比较消耗 CPU 资源的。因此智能网卡,也就是 DPU,就可以做集合通信的卸载。
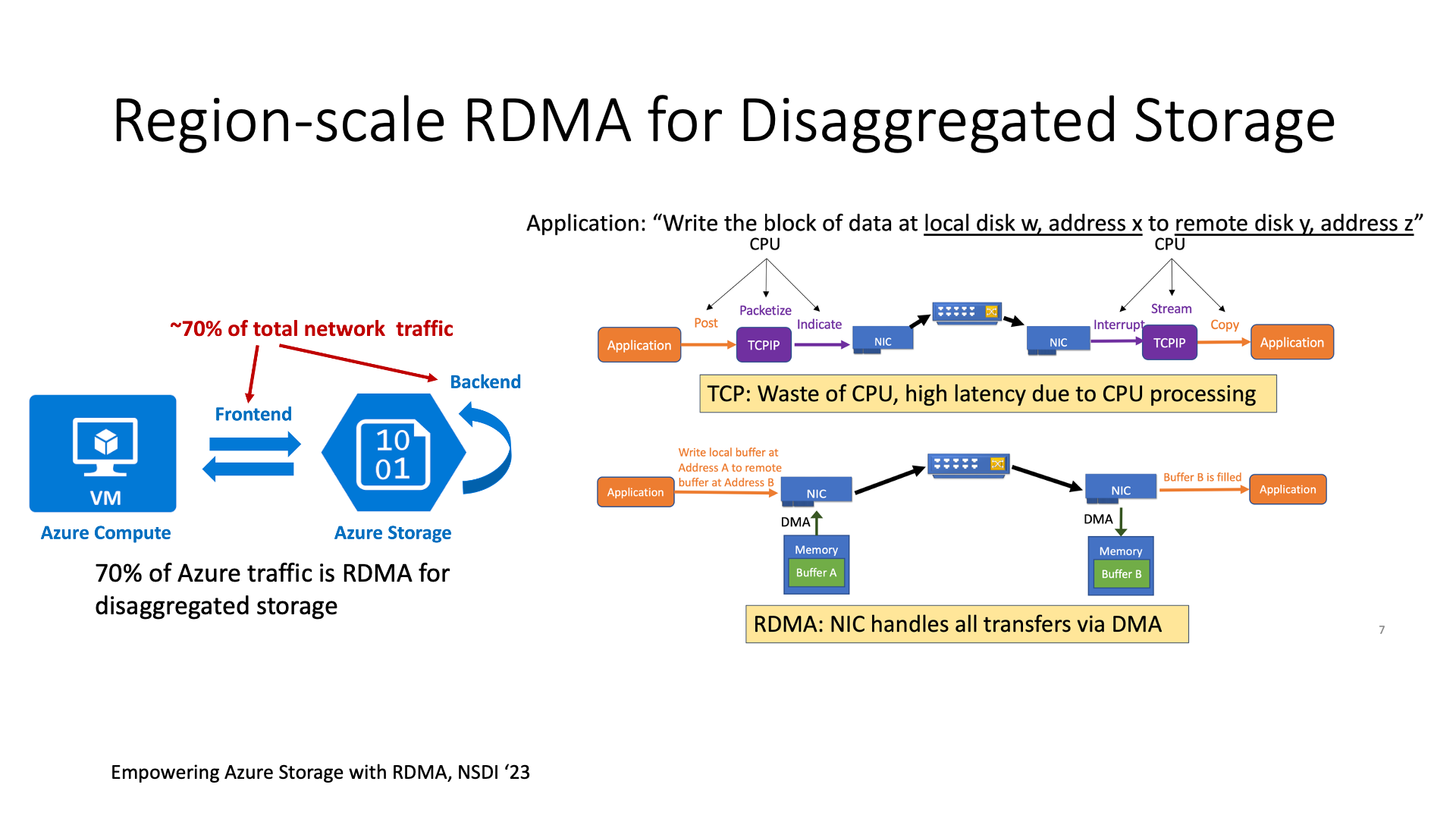
在 Cloud 网络方面,RDMA 是一个非常好的技术。下面我们介绍一个目前世界上最大的 RDMA 部署,就是微软 Azure 全网部署 RDMA,主要用于加速云存储。
微软这个 RDMA 部署有什么特别的呢?之前的 RDMA 部署都是在一个 cluster 内部,最多是到一个 data center 的级别。但微软的 RDMA 部署是整个 region,在一个 region 中,跨数据中心的通信也全部都使用 RDMA 来做。
这里的 RDMA 并不是 Infiniband,而是 RoCE(RDMA over Converged Ethernet)。IB 是做不到跨数据中心的。
在微软 Azure 的整个网络中,70% 以上的网络流量,其实都是对存储的访问,这是非常容易理解的。因为存储都是 disaggregated 的,在专门的存储集群中。所有的 block 存储、NAS 盘、object 存储的访问都要经过它,所以其实存储系统产生的通信带宽甚至比主机之间直接产生的通信带宽都要高。
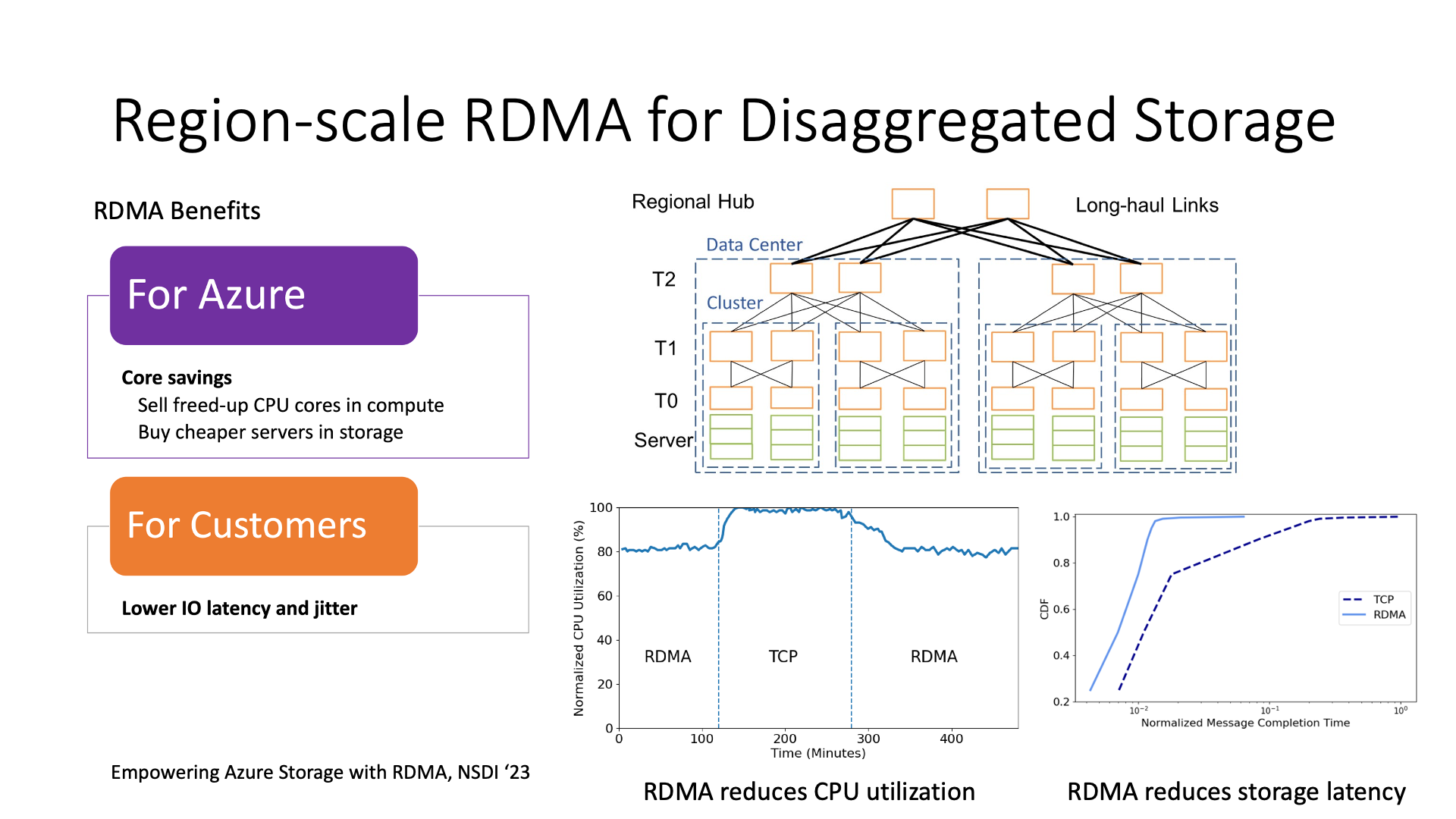
用 RDMA 取代 TCP 可以在计算节点上减少很多 CPU 的浪费。比如说在这个图中,它显示了使用 RDMA 的 CPU 使用率比使用 TCP 的要低 20%。存储节点也可以降低成本,因为如果存储节点都使用 TCP,那就意味着它需要很多的 CPU 用来处理网络。如果使用了 RDMA,它可以节约网络所消耗的 CPU,进而就可以用更便宜的 CPU 来做存储节点。
另外一个就是对延迟的一个下降,特别是延迟抖动的下降,也就是 tail latency(尾时延)相比 TCP 可以显著降低,这对提升存储系统的 QoS 是很关键的。

Region 级别部署 RDMA 这里面的主要挑战其实就是在拓扑图里最上面这些跨 data center 的交换机。如果要在一个几十台机器的小 cluster 内使用 RoCE,其实相对来说还没那么难,基本上是开箱即用的。
如果 RDMA 要跨数据中心,然后要通过上面这些跨 data center 的这些距离,大约 100 公里,那么这里就会带来一个挑战。因为要做到消除拥塞丢包就需要 PFC(Priority-based Flow Control),它是 hop-by-hop 的,也就是上一跳的 buffer 大小必须足够容纳得下这两跳之间一个 BDP(Bandwidth-Delay Product)的报文,那么 100 公里的 100 Gbps 连接,就需要 1 毫秒的 RTT,也就是 12.5 MB 的 BDP。每个端口都需要这么多 buffer,普通交换机的 buffer 就容易不够用。
因此,微软 Azure 买了一些大队列的交换机,其实现在最顶级的交换机 buffer 都是很大的,然后将 buffer 调整成共享队列,而不是每个端口固定占一定内存的队列。
他们还做了很多与网卡和交换机配置相关的工作。比如很多人担心的 DCQCN 拥塞控制算法。其实 DCQCN 由于是 rate-based 而不是 window-based,有一个很好的特性,它不会导致 RTT 高的连接和 RTT 低的连接在竞争时受到不公平对待。例如,在互联网上,如果一个跨国的连接和本地的连接在竞争,跨国的连接肯定会吃亏。但在 DCQCN 中,跨 data center 的连接和 data center 内部的连接是公平的。当然,他们也对 DCQCN 的参数进行了一些调优。
但是问题比较大的 PFC。当规模变大后,比如说它不再是一个千台机器的集群,而是一个十万台机器的集群,这意味着很多网卡会故障,很多交换机会故障。这些故障的网络设备有可能会产生很多的 PFC 报文,无休无止,把整个网络堵死,这就叫做 PFC 风暴。
PFC 本来是用来做流控的,它可以反压,让上一跳不要发送过多的数据,这样可以尽量减少丢包。但是,传统上很多研究人员都提出,既然 PFC 有风暴的问题,有死锁的问题,那么我以后就彻底不用它了,我只靠端到端的拥塞控制。但是实际上,端到端的拥塞控制并不能完全解决所有的问题。
比如我们在很多个节点同时访问同一个节点的情况下,也就是所谓的 incast 情况,不管使用什么拥塞控制算法,最后都会造成拥塞。这时候我们还需要依靠 hop-by-hop 的 PFC 来控制网络的流量,保证网络不会因为拥塞而丢包。
微软 Azure 的解决方案就是保留 PFC,但是能区分它是由故障产生的 PFC,还是由拥塞导致的 PFC。逻辑其实很简单,因为如果它是由故障导致的,它会源源不断的发送,如果是由拥塞导致的,它会堵一下,后面就不会再堵了。所以,如果遇到由故障产生的 PFC,交换机和智能网卡会将这些 PFC 过滤掉,并且上报一个故障。
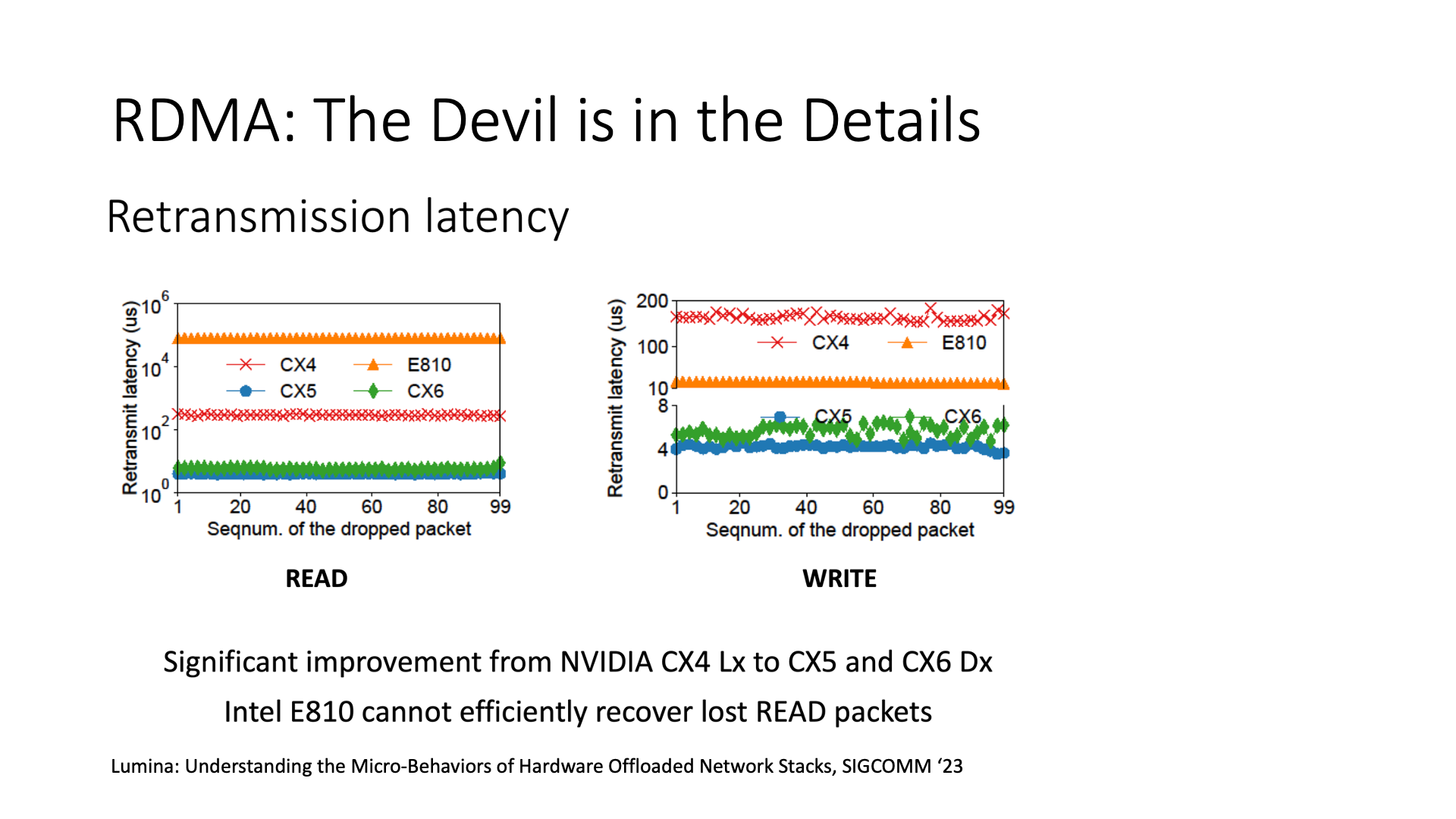
部署智能网卡的过程可能会很复杂,因为不同的网卡行为各异,有些网卡的性能可能会较差。例如,如果你使用特定的网卡,比如图上的这款 Intel 网卡,其丢包恢复的时间可能会非常长。这种事情是不会写在网卡的 spec 里的,甚至简单用 perftest 测一测都发现不了,只有在有丢包的环境里才能测出这个问题。这就像我们选 GPU 一样,不是说理论算力看起来高就一定更好,魔鬼都在细节里面。
再举个例子,不同网卡之间的互操作是个很麻烦的事情,因为它们的实现不一样。比如老款的 Mellanox 网卡是遇到拥塞一个 RTT 内只返回一个 CNP 拥塞通知报文,发送端收到这个报文就降速一半;但新款的 Mellanox 网卡是每个拥塞报文都返回一个 CNP 通知,发送端收到这个报文只是降速很小一部分。那么如果老款和新款的 Mellanox 网卡放到一起通信,老款往新款网卡上发数据的时候遇到拥塞,那么新款网卡返回了一大堆 CNP 报文,老款网卡一下子就把速度降到接近 0 了,这个性能肯定就不能看了。

在使用 RDMA 网卡时,也会有很多安全性问题。
例如,DoS(Denial of Service)攻击,如果一个连接有很多的 RNR(Receiver Not Ready)错误,即当发送的 send 请求没有对应的 recv 接收请求时,网卡就会返回 RNR 报文。但是网卡处理这个错误报文是使用网卡内部的固件,而固件处理速度较慢,所以一旦开始处理大量的 RNR 报文,其他的操作都会变得非常缓慢。这就是破坏了 RDMA 网卡的性能隔离。

微软在大规模部署 RDMA 的过程中,也有许多发现。首先,故障处理问题比较麻烦。其次,主机和物理网络需要协同工作,这也是像英伟达这样的公司正在解决的问题。第三,如果距离过远,现有的交换机缓冲区就不够用了。如果要做一个跨 region,数百公里甚至上千公里的 RDMA,那么现在的交换机缓冲区就不够用了。此外,如果在云上面对不同的虚拟机,有些网卡的性能可能会很差,这时需要统一的行为,这也是一个比较麻烦的问题。
对于 RDMA,如果要大规模部署,它需要面临很多问题。可以将 IB(InfiniBand)视为企业版的 RDMA,而 RoCE 可以理解为社区版的 RDMA。社区版可以更好地进行调优,但是各种奇奇怪怪的问题需要自己解决,而企业版的 IB 基本上是开箱即用,但规模可能就不会很大。例如,它无法解决 100 公里的连接,无法互联两个数据中心,所以如果想实现这种 region 级甚至的部署,还是需要使用 RoCE 方案进行调优。

针对 AI 中的网络挑战,主流的解决思路是通过网络拥塞控制(congestion control),或者使用流量控制(flow control)。这两种方法的区别在于,流量控制是解决端上的停车场堵塞问题,拥塞控制是解决马路上的堵塞问题。如果过度优化马路上的拥塞控制,可能会使得端上停车场堵塞的问题更加严重。
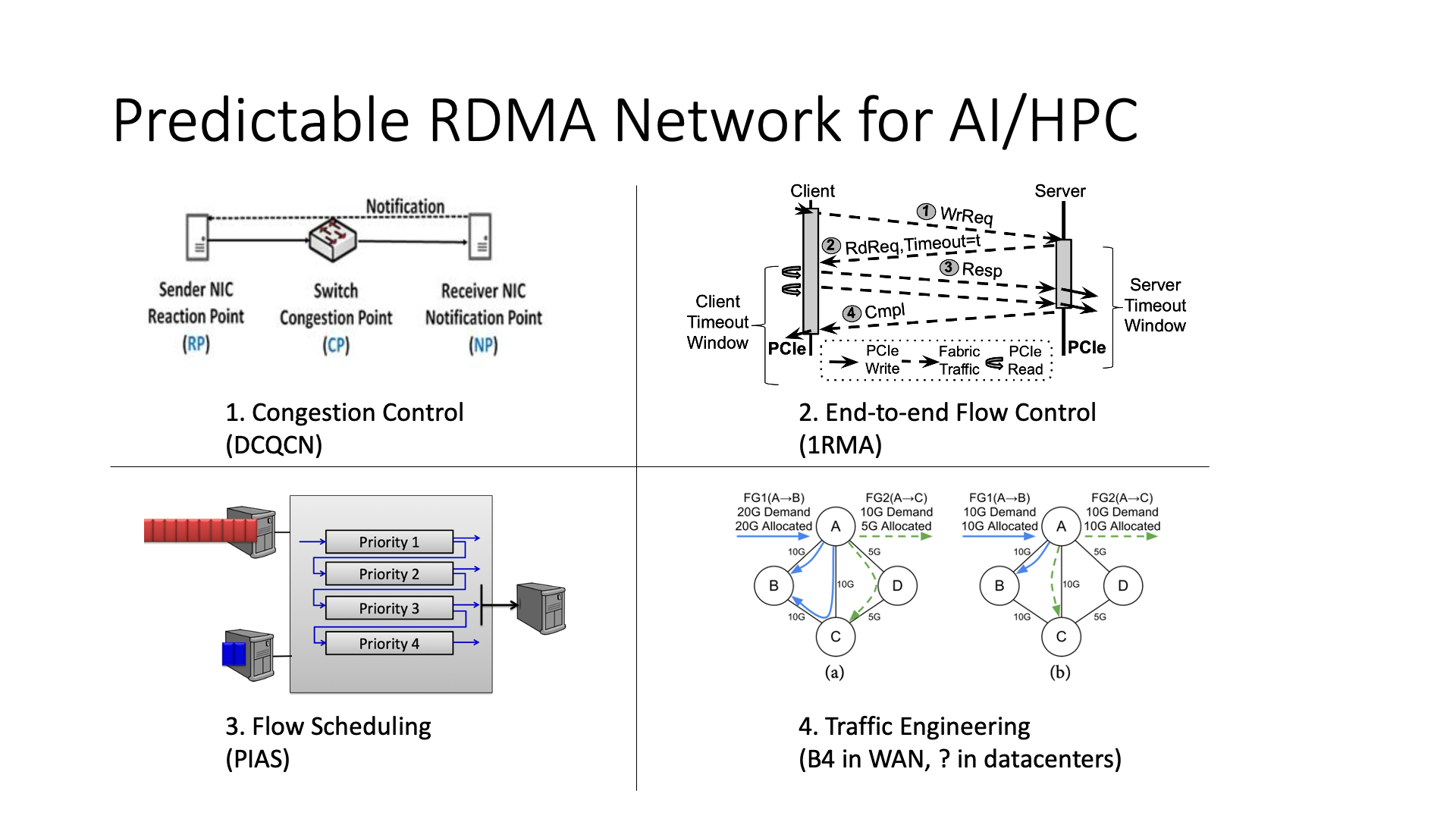
AI 的 workload,特别是 Transformer 这些大模型,有一个很好的特性,那就是它们都非常可预测。
传统的拥塞控制和流量控制都是一些响应式的解决方案,也就是发现网络拥堵了,我再去降速。
更进阶一点,Flow Scheduling(流调度)一般是需要 flow size(流大小)的信息,就可以优先传输小流,实现最低的 FCT(Flow Completion Time)。
最极致的可以说是 Traffic Engineering(流量工程)了,也就是事先就规划好都有哪些流要传输,算好每条流走哪条路,把网络里面多条路的带宽都给充分利用起来。流量工程的方法主要用于广域网,但很少有人将其用于数据中心,因为人们一般认为数据中心的流量很难预先计算。但在 AI 中,流量是可以预先估计的,因为在训练之前,我们就知道每次要传输的 tensor 有多大。
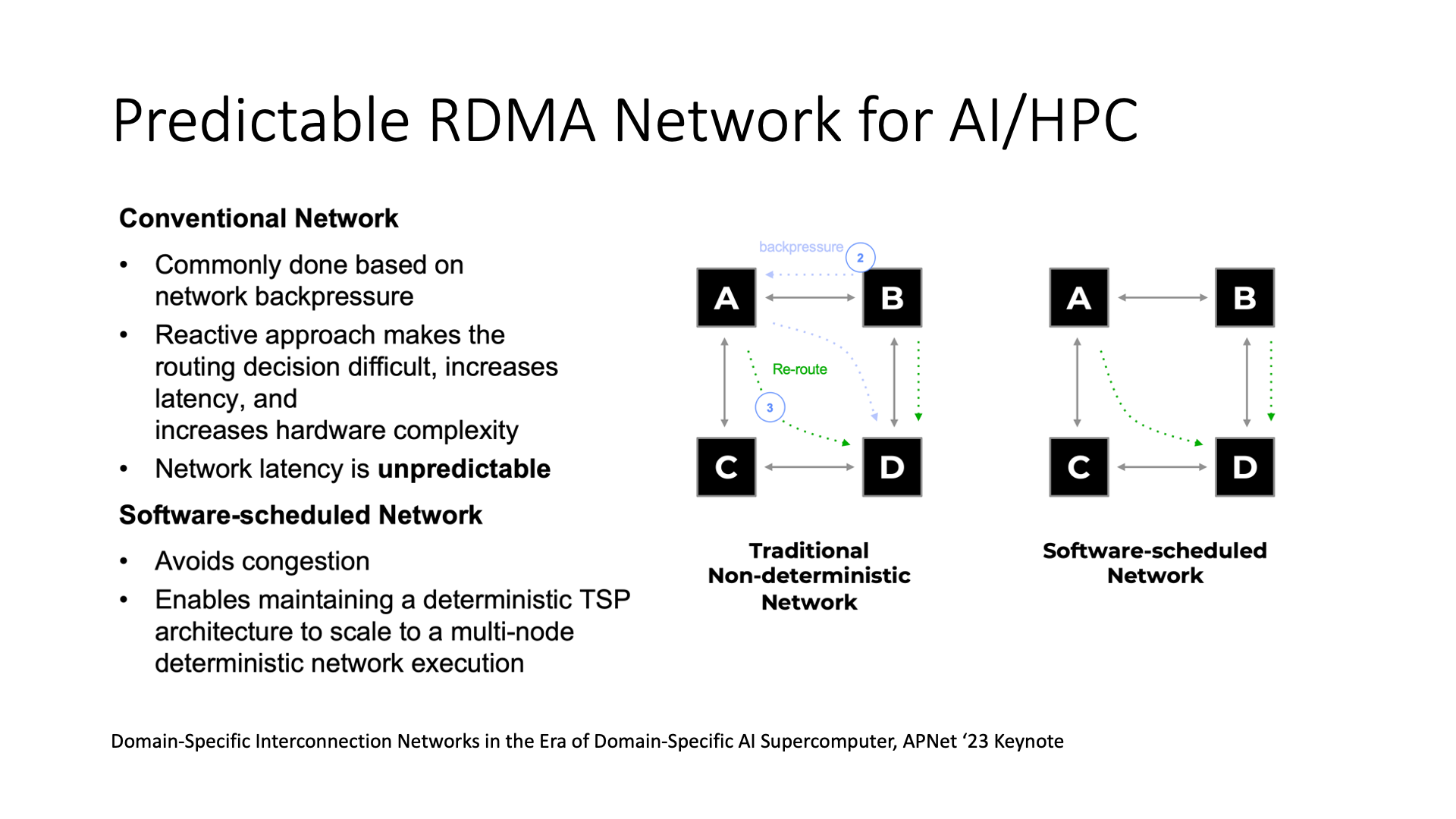
在 AI workload 中,就有一些新的方法可以使用,例如软件调度的网络。传统的网络是在发现拥塞后进行调整,例如换路(adaptive routing)或者反压(back-pressure)。而在软件定义的网络中,可能一开始就能规划好每条流走哪条路,这样 AI 通信的效率可能会更高。
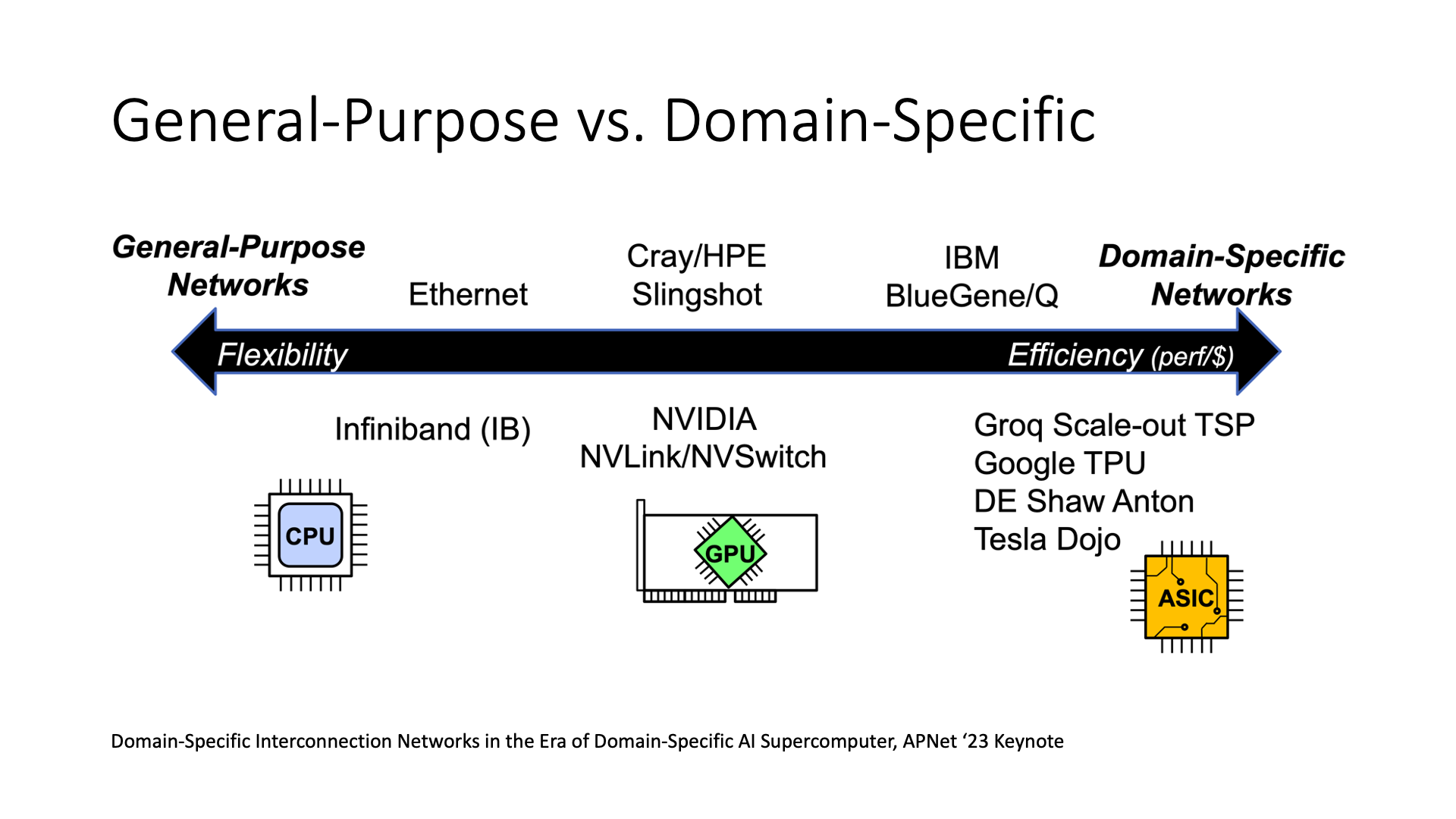
但这也引出了一个问题,每条流走哪条路都提前算好了,这个网络是通用网络还是专用网络?
如果我已经规划好所有东西,甚至不仅是软件层面的规划,还包括将其实现在硬件中,例如现在的 Groq、Dojo 这些 ASIC,它是一种非常专用的网络通信设备。在这种情况下,它的效率会比较高,因为它是专用的。效率低的以太网、IB 就是通用的。
但是也有一些处于中间状态的,比如 NVIDIA 的产品,兼顾了通用性和性能。

那么到底应该做通用的还是专用的?我个人觉得并不是一定要追求性能最高的架构,为什么呢?就像 GPU 和 DSA 这样的例子,GPU 就是 NVIDIA 一直在推广的产品,它有一个很好的生态系统,因为它投入了大量的精力去开发这套软件的生态系统。但是,DSA 在同等的芯片工艺下,它的效率肯定比 GPU 要高,可能能高出 50%,甚至翻倍。
但是问题在于,DSA 的编程就很麻烦,经常有很多算子不支持,光是开发就很困难。所以如果这个设备的编程能力差,生态系统可能就不会很好,最后这个设备可能也不好销售。
另外就是可扩展性的问题。这里的可扩展性一个是指大规模下是否可扩展,比如 IB 就没法跨数据中心,而 RoCE 可以跨数据中心。另外一个是指应用场景的可扩展性。
比如 DSA,像华为做的 Ascend,最早是为了 ResNet 定制的,是因为 2016 年的时候大家都在研究 ResNet,但是现在流行的是 Transformer,需要的东西跟 ResNet 完全不一样了,那款芯片的有效算力只有 30%。所以现在又有了新一版的 Ascend,可以再针对 Transformer 做一些优化,这样有效算力就比上一代的 Ascend 提升了 3 倍。
但是在这个研发下一代 Ascend 的过程中,NVIDIA 已经卖了好几年 GPU。等到新一代的芯片全面铺开,再过两三年,可能 Transformer 又不火了。所以 DSA 架构总是存在这样一个通用性的问题。
实际上,芯片的制造成本是比较低的,比如说 H100,如果我去看它的制造成本可能就 2000 美金,但是实际上它能卖到 3-4 万美金。如果我做了一款芯片,即使为了通用性牺牲了一点性能,我也可以给它多做一些面积,制造成本高一些,多耗一些电。甚至我们可以用多块芯片去打一块芯片,除了耗电多点,它的性能也能做到比较好,整个盈利空间其实仍然是很大的。所以我认为可编程性和可扩展性是更重要的。

最后,我们做一个简单的总结。我们有基于 ASIC 的、NP 的、FPGA 的和 DPU 的这些不同架构的智能网卡,以及可编程交换机,同时我们还有基于内存语义的高性能互联,比如 NVLink 和 CXL 可以实现设备之间点对点的直接通信,同时把主机内和主机间的互联融合到一起,此外 AI 和云计算也不再是独立的集群了,而是融合到一起的统一算力平台。
那么在这样的一个整体的架构底下,我们可以说智能网卡(SmartNIC)主要是为了做虚拟化,交换机(Switch)可能更多的是让系统能够感知到网络的状态,然后进行各种实时的调整。如果是 GPU、NPU 和存储之间的通信,因为它的效率需要非常高,所以可能基于内存语义的直接通信是最合适的。
那么有一个比较有意思的地方,就是说算力放到哪里都有可能,放到每个地方都有它不同的优点。未来是一个 AI 的世界,每个计算设备和网络设备可能都是很智能的,所以我们就看把什么样的工作负载放到什么地方会更加合适一些。谢谢大家。

非常感谢李博杰的分享,如果有任何问题,可以在腾讯会议上直接提问。
问题 1:我们提到了 GPU,那么跨机器的 NVSwitch 是否是必要的?
回答 1:在 70B 左右大小模型的训练中,最关键的是 Tensor Parallelism(张量并行)里面的通信,流水线并行和数据并行里面的通信量都不算很大。对于张量并行,一般来说就是在主机内部的 8 卡之间能够有一个高性能的 NVLink 互联,这个是不可以用 PCIe 或者 RDMA 取代的。但是跨机器的流水线并行和数据并行走 RDMA 就足够了。
但是对于更大的模型,比如 GPT-4 这种上千 B 的模型,单机 8 卡做 Tensor Parallelism 也是不够的,这时候就需要跨机器的 NVLink 互联。就目前来看,256 卡 NVLink 互联已经基本上够用了。这 256 张卡基本上正好可以放进一个加强版的 rack,这就是所谓的超节点,也就是把整个 rack 内部都做成超高速的互联,通信效率就像在一个节点内部一样。
问题 2:对阿里倚天 CIPU 架构里的 multi-hosting 怎么看?multi-host 是否可以降低故障率?
回答 2:如果我只有一个网卡,我可以将其虚拟化为两个网卡,这是一种减少网卡成本的方式。但是其问题在于,故障域反而是扩大了。本来两台机器的两个网卡故障是互相不影响的,但是做了虚拟化之后,只要这个物理网卡故障了,两台机器都没办法访问网络了。
如果把两台机器虚拟化成一个机器,问题在于,其内存并未进行复制,我认为这反而会增加故障范围。原来我的内存都在本地,现在这样做之后,部分内存存储在本地,部分存储在远端,如果远端机器出现故障,那就会有问题。
问题 3:现在通过 NVLink 连接的带宽要比 PCIe 的带宽要宽很多是吧?
回答 3:对,肯定的,因为 PCIe 现在最快的也就是双向 128G,而 NVLink 的双向带宽是 900G,等于说它的带宽是 PCIe 的近 10 倍。
问题 3:现在有没有比如说我自己设计 ASIC 的一些方案,倒也不一定是 CPU 与 CPU 之间的,我在想有没有那种类似 SoC 这种设计,CPU 和 CPU 之间包括数据共享是通过高速总线,就是说它有部分的内存是可以通过 GPU 来进行搬运,这种缓存的话是不是要比 RDMA 会更快一点?
回答 3:在某种场景之下可以的。实际上华为的 Unified Bus 就是这么做的,这里边实际上有点像苹果的 Unified Memory,他做的事情就是把 CPU 和 GPU 用的同一块内存,当然因为它是桌面的,所以说它可能就只有 400 GB/s 的通信带宽对吧?它没有搞得特别高,但是服务器的话它可以搞得更高,就是可以搞到大几百 GB/s 对吧?甚至上 TB/s 都是可以的。
其实本质上跟英伟达这个 Grace Hopper 架构也是一样的,你看这张 Grace Hopper 的架构图里边它的内存,这张图里面虽然没画内存,但是我们知道内存也是共享的,这里面有 144 TB 的共享内存,CPU 和 GPU 都可以直接去连到上面去,这个里边 CPU 和 GPU 之间通信的带宽也是非常高的。
问题 3:这里的共享内存实际上也分远端和近端内存的是吧?
回答 3:对,肯定还是有区别的,比如说像 GPU,它如果访问自己的内存肯定效率最高,因为它的带宽比如说 H100 它是 3.35 TB/s,然后但是你从外边的,它其实也就是 900 GB/s 还是双向的,单向的 450 GB/s 其实也就是差 10 倍左右了。
而且 GPU 在访存的时候,因为它是并行去抓的话,速度应该是更高。但 CPU 的核数比较少,每个核里面没有多少个 outstanding 内存请求,它实际上是串行的。而且 GPU 里面还有 Tensor Core,一次抓进来是一个矩阵,这个计算效率就更高了。
问题 4:昨天正好也有一个群里面在讨论这个问题,就是说实际上现在不管是大模型还是什么的,这种训练加速的实际上而言都是英伟达在领导这个趋势,而且所有的东西在相当于做一些特性,包括说是模型本身设计都是按他的 GPU 的这套东西,CUDA 架构这套东西来去做的,所以说是不是像业内去做一些东西的话,很难超越它。其实就是说你做着发现就是说实际上他又在做一套更领先的东西,你很难去在短期内去跟上它,然后过段时间它又有更新的东西出来,而且它也是在一个持续发展的过程当中。他不像就是说 CPU 这一块,像英特尔其实早就摩尔定律失效了,大家可以在某个点上跟他做一些竞争。
回答 4:我觉得它主要还是取决于一个定制化架构的问题,比如说是比如现在有好多这种 DPU,它实际上都是自己定制的,而且像 Wafer-Scale Chip 这种东西它中间的带宽超级大,带宽可能比 NVLink 还要大对吧?都是上 TB 的,然后整个 Wafer 上面的所有芯片全都直接连起来了,对吧?这些都是一些比较新的架构,可以在一些特定的 workload 上面,表现出比英伟达更高的性能。
但是我认为,这其中存在一个核心问题,即模型和硬件的共同演化问题。就如我之前所说,当我们进行模型设计,或者设定优化目标时,我们会考虑模型在硬件上的执行效率。例如,Transformer 的设计者在设计时的主要目标就是提高效率。他们并没有一开始就过分追求精度,而是着重于并行化计算,使得其计算速度比传统的 RNN 更快。现在大多数的模型都是为 GPU 优化的,那么新的架构如果不够通用,就很容易赶不上模型的进化。
我们前面讲过一个 10-100-1000 的规则,其中的 10 就是说这个 workload 至少要能用 10 年。如果做的太定制化,用 10 年这个目标就没法达成。所以不管是微软 FPGA 的 GFT 卸载,还是 AWS Nitro 里面的流表,或者 NP 和 DPU 里面的流表,都是有一定的通用性和可编程性的,不是说就为了当前云上的虚拟化需求定制一个。
问题 5:看这张图,左边的通用架构灵活性非常高。右边的是垂直设计,整个软硬件都是为了未来需求而定制的,这样更为理想。但是与 GPU 相比,尽管 DSA 在处理大模型等方面有优势,但在许多模拟计算上,它仍然具有通用性。
回答 5:对,左边这种通用设计用来做高性能计算(HPC)毫无疑问是可行的。但是右边的 DSA 设计很难实现高性能计算,它的有效算力就会大打折扣。这就是 DSA 的问题。
问题 5:GPU 在处理稠密数据时表现优秀,但是在处理稀疏矩阵,例如稀疏数据计算时,Tensor Core 的性能相对较差。
回答 5:对,稀疏矩阵计算的效率确实较低。所以现在有很多研究 FPGA 和 ASIC 的人,他们都在尝试如何在稀疏和量化上进行加速。
FPGA 我认为目前超越 ASIC 是非常困难的,因为同样规模的逻辑,FPGA 的效率可能比 ASIC 低 10-100 倍,一方面是 FPGA 的频率远低于 ASIC,另一方面是 FPGA 里面每个可编程门占的面积比 ASIC 又要大几倍,这就是可编程性的代价。
前面讲这个 FPGA 卸载的 10-100-1000 规则的时候,100 指的就是 100 行 C++ 代码,在我们 2015 年的时候,FPGA 的面积还很小,放不下多少逻辑。今天的 FPGA 面积大多了,但是也只能放下 1000 行 C++ 代码量级的逻辑。但我们前面也讲了,一个完整的 RDMA 实现需要 10000 行 C 代码的量级,完全放进 FPGA 里是不现实的,只能把热路径放进去,这样就意味着冷路径还得在 FPGA 旁边搞一个小核。
其实 ASIC 化的 Mellanox 也是这么干的,前面我们讲 RNR 是个容易导致 DoS 攻击的漏洞,就是因为 RNR 的错误处理是在固件上面执行的,而不像正常报文的路径那样是在 ASIC 里面处理的。但是 ASIC 里面放同样的热路径所占的面积和功耗,那是比 FPGA 小多了。所以你看 Mellanox 的网卡都是 VPI 卡,既支持 IB 又支持 RoCE,还支持一大堆加速能力,要是这些逻辑都想在 FPGA 里面实现,肯定是放不下的。
在 DSA 方面,我认为量化加速超越 GPU 有些困难,因为现在 NVIDIA 在量化上,包括最新的 H100 等,已经做了很多工作,包括 8 bit 的性能已经很高了。但在稀疏计算上,我认为 NVIDIA 的工作还相对较少,目前稀疏的 flops 只是稠密的 2 倍,如果真的 0 占比很高的话,这个性能还是比较差的。DSA 有很大的优化空间。
在一些比较早期的大模型训练中,以及推荐系统这些传统 AI 算法中,稀疏计算占比较高。但是,如果是基于目前的 Transformer 架构来说,它的占比应该不高,因为 Transformer 都是一些稠密的矩阵。但是如果未来的 Transformer 可以变成稀疏的,可能也有其意义。
但我认为现在盲目追求稀疏可能不一定效果很好。之前华为做的盘古模型很早就号称是万亿级模型了,相当于是上千 B 的模型,但是那个模型里面是稀疏的,也就是它实际的参数量和算力都远远没有达到万亿那么高。因此,它最后的准确率并不理想。所以现在新版的盘古大模型又是基于 Transformer 的架构重新做的,准确率就比原来大大提升了。
如果稀疏计算未来真的很重要,说不定 NVIDIA 又会推出个 sparse core,作为 tensor core 的补充。我们看到 2016 年英伟达把第一台 DGX-1 送给了 OpenAI,他们很早之前就在合作,意识到 tensor core 很重要,意识到大规模分布式训练很重要,意识到网络带宽很重要。所以搞 AI 芯片的厂商一定需要跟靠谱的大模型公司深度合作,才能知道未来的模型是什么样的,需要什么样的算力、存储和通信。
(完)